

目录
网络层概述
网络层在数据链路层提供的两个相邻端点之间的数据帧的传送功能上,进一步管理网络中的数据通信,将数据设法从源端经过若干个中间节点传送到目的端,从而向运输层提供最基本的端到端的数据传送服务。

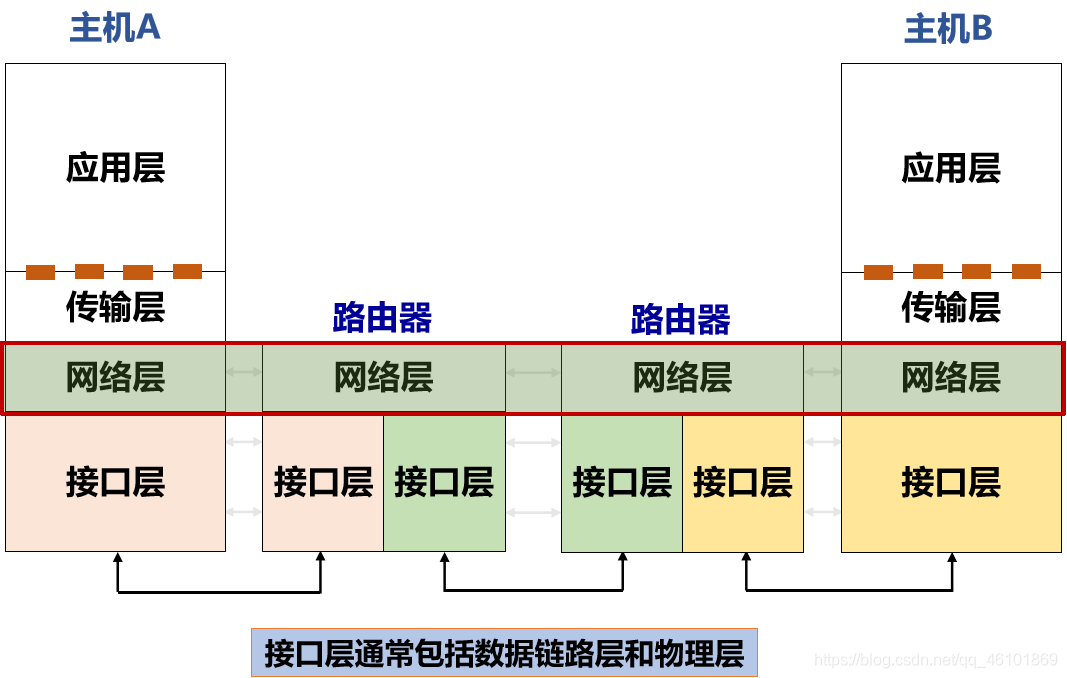 数据链路层与网络层的区别
数据链路层与网络层的区别

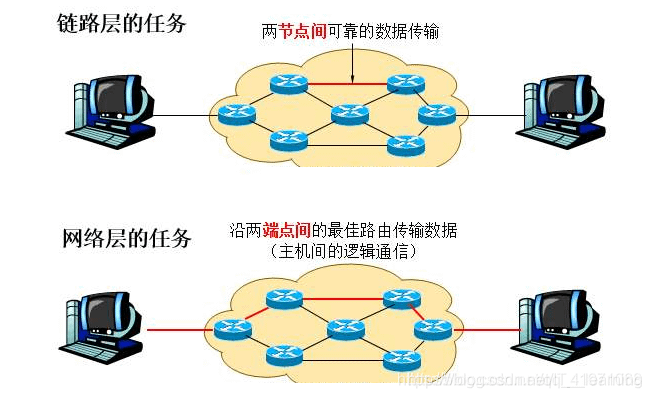

网络层关键功能
-
路由(控制面)
选择数据报从源端到目的端的路径核心:路由算法与协议
-
转发(数据面)
将数据报从路由器的输入接口传送到正确的输出接口
https://blog.csdn.net/yutong5818/article/details/80685715

网络层提供的两种服务
面向连接服务与无连接服务
https://blog.csdn.net/weixin_42134168/article/details/118230940
面向连接服务的含义是,在开始发送信息包之前发送端和接收端要进行沟通,建立直接连接,并提醒对方准备接收信息包,然后才开始进入信息包的传送过程。例如,我们打开电话时,要和某个人通话,先拿起电话,拨号码,谈话,然后挂断等过程。
无连接服务的含义是,发送端简单地把信息包送到网络上,在传送信息包之前发送端和接收端没有沟通的过程,也没有对方来的确认,因而也不知道目的地是否接收到。无连接服务既没有拥挤控制功能,也没有流程控制功能。例如,在邮正系统为中,每个信件带有完整的目的地址,并且每一个信件都与其它信件不同,由系统选定的邮件的地址传递。
虚电路和数据报网络
虚电路网络
虚电路网络:在网络层提供面向连接的分组交换服务。双方通信前先虚电路建立连接,通信结束后再拆除连接。
虚电路(virtual circuit):源主机到目的主机的一条路径上建立的一条网络层逻辑连接。

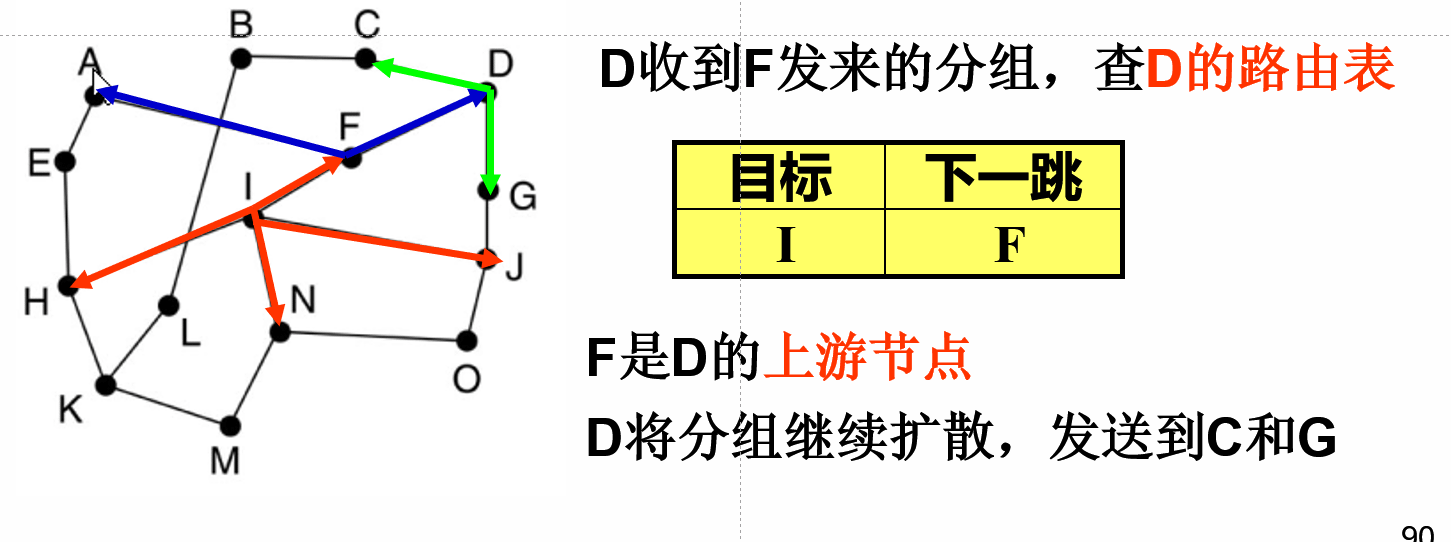
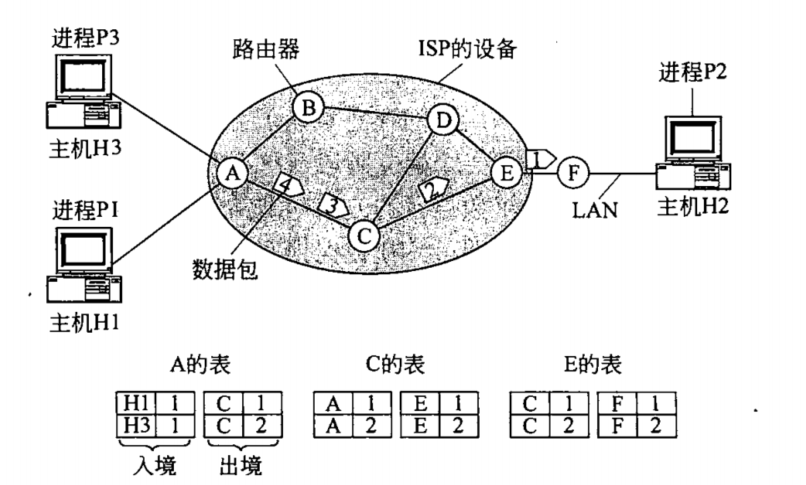 对于每一个路由器,都有一个对应的表。
对于每一个路由器,都有一个对应的表。


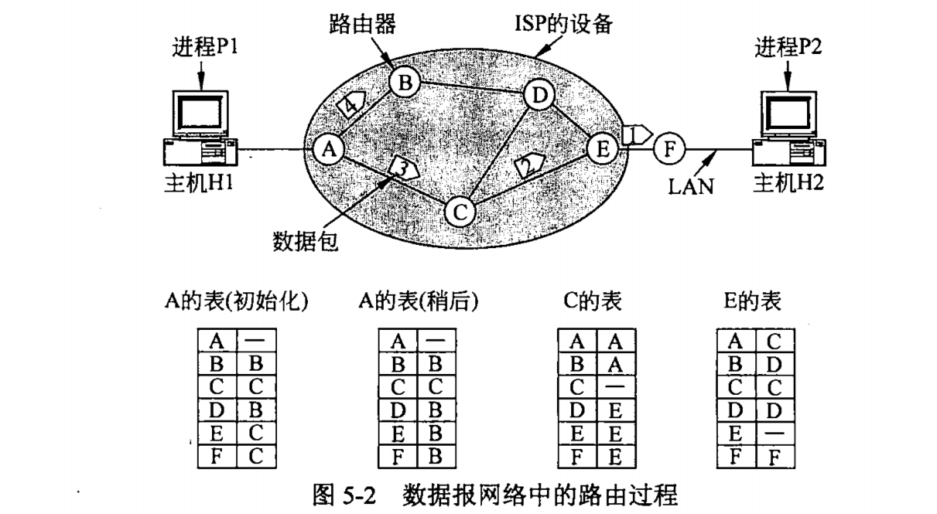
数据报网络
数据报网络:无连接的网络服务。
源主机每要发送一个分组,就为该分组加上目的主机地址,然后将该分组推进网络,每个路由器使用分组的目的主机地址转发分组。不需要建立源到目标的“电路”
对于每一个路由器的表上,都记录到达目的主机所需的下一个路由器的序号。

比较


路由算法
路由算法作用: 计算目标网络之间的距离
优化原理
贪心算法
- 如果路由器J在从路由器I到K的最佳路径上
- 则从J到K的最佳路也在同一路上
静态路由
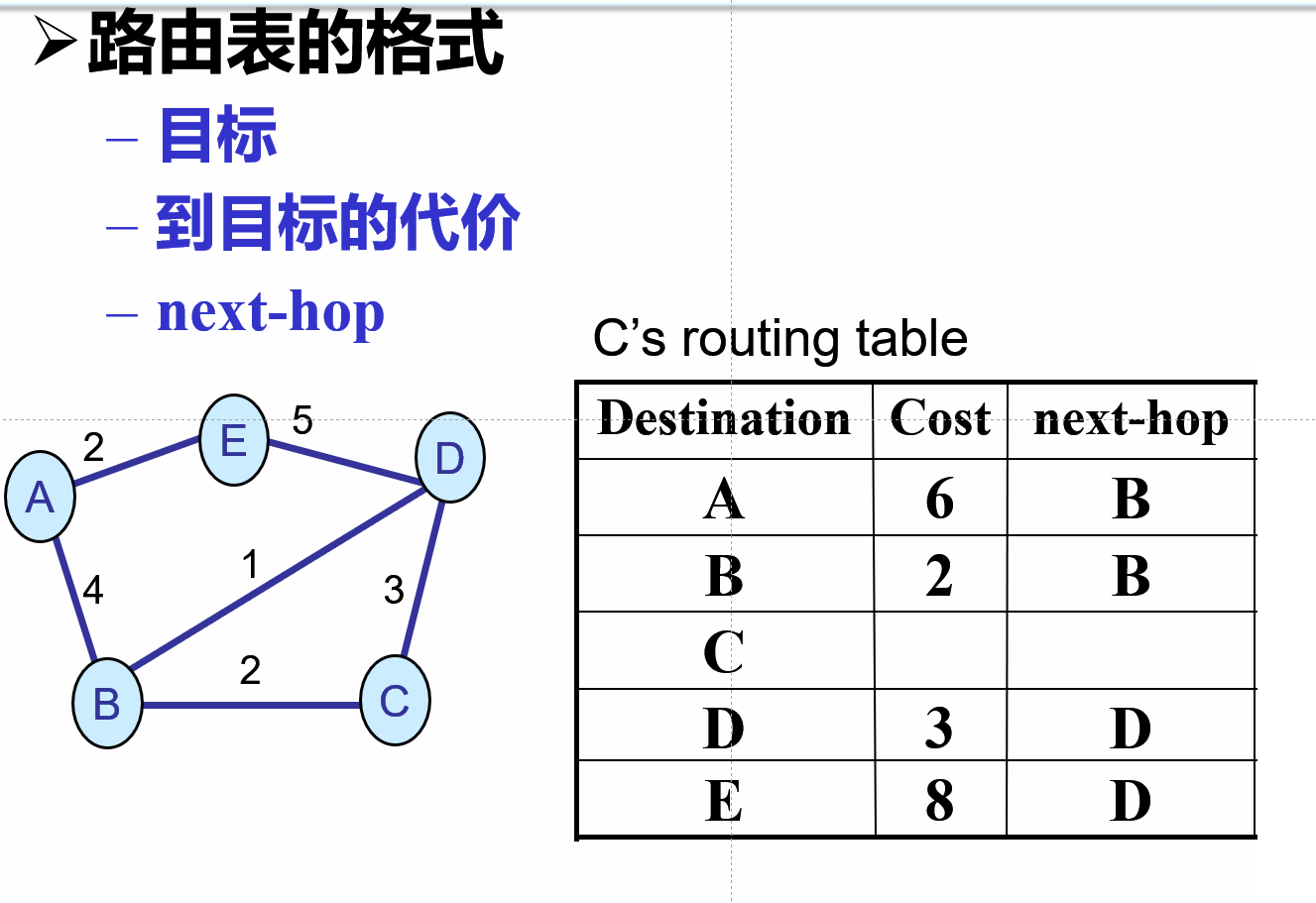
距离矢量算法
每个路由器维护一张表(级一个矢量),表中标出当前一直的到每个目标的最佳距离,以及所使用的链路。




路由表

无穷计算问题
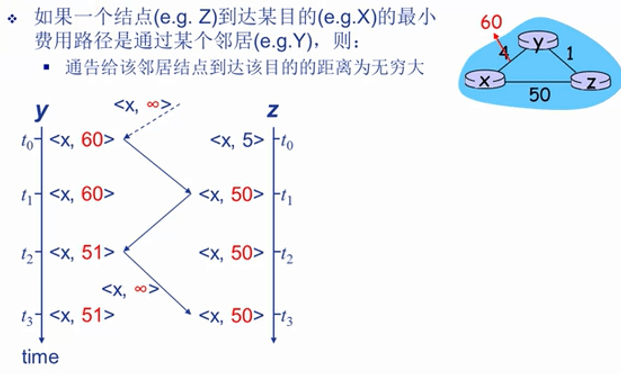
在链路费用低时,传播速度会比链路费用上涨时传播的更快.
也就是离得近的发的先到,离得远的发的后到。

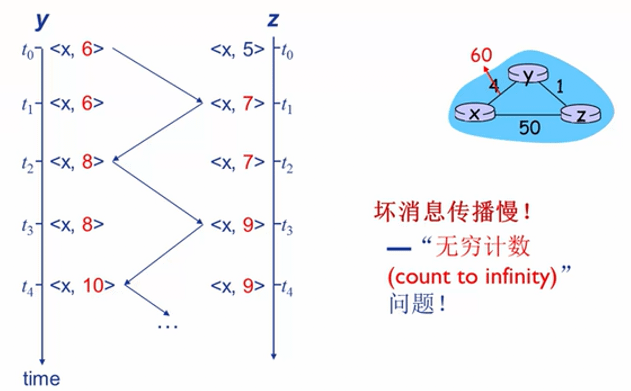
上图清晰的描数了链路费用上涨时的费用更新情况.在T0时间,dy(x) = 6 ,dz(x) = 5.
t1时段Y发现了y-->x这个链路的费用上涨,进而更新了自己的CV.
式子: dy(x) = max{cy(x),cy(z)+dz(x) } = {60,1+5} = 6
所以 dy(x)变成了6 ,这显然是不对的.
因为dz(x) 的值是基于dy(x)获得的,在dy(x) 发生变化的时候dz(x)的值就应该失效了.也因为这一问题,导致了无穷计数的问题
无穷计算问题解决方法
-
1、毒性逆转

-
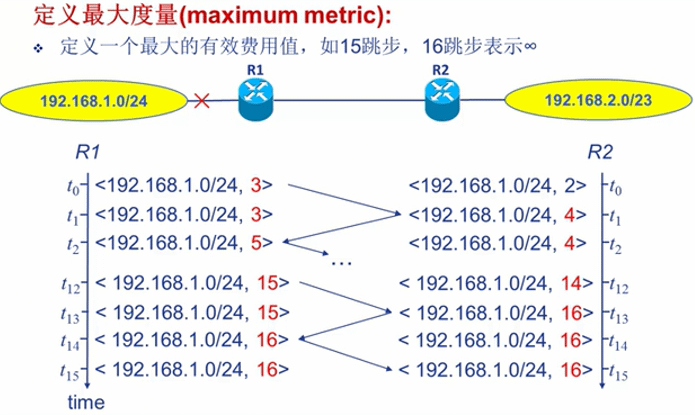
定义最大度量
定义一个最大的有效值,超过该值的值就认为是不可达,不再更新.这就相当于为死循环增加了一个结束条件.


链路状态路由
思想:
发现它的邻居节点们,了解它们的网络地址
设置 到它的每个邻居的成本度量
构造 一个分组,包含它所了解到的所有信息
发送 这个分组给所有其他的路由器
计算 到每个路由器的最短路径
1 发现邻居节点
当一个路由器启动的时候,在每个点到点的线路发送一个特别的HELLO分组
收到HELLO分组的路由器应该回送一个应答,应答中有它自己的名字 (采用一个全球唯一的名字 globally unique name)
2 设置链路成本
为了决定线路的开销,路由器发送一个特别的 ECHO 分组,另一端立刻回送一个应答通过测量往返时间(round-trip time),
发送路由器可以获得一个合理的延迟估计值,为了得到更好的结果,可多次测量,取均值
一种常用的选择:与链路带宽成反比
3 构造链路状态分组
链路状态分组构造后被发送给其他的路由器,分组中包含这些信息:
1 发送方的标识(ID of the sender)
2 序列号(sequence number )
3 年龄(age )
4 邻居列表(list of neighbors )
5 到邻居的成本/量度(delay to each neighbor )
应该什么时候构造分组?
周期性地构造和发送,或者有特别的事件发生时构造,比如某条线路或邻居down掉了


4 发布链路状态分组
基本算法:
每个分组都包含一个序列号,序列号随着新分组产生而递增
路由器记录下他看见的所有 (源路由器,序列号)对
当一个的新的分组到达时,路由器根据它的记录:
如果该分组是新的,就被从除了来线路外的所有其他线路转发出去 ( flooding,泛洪)
如果是重复分组,即被丢弃(喜新厌旧)
如果该分组的序列号比对应的源路由器发送的到过此地的分组的最大序列号还小,则该分组被当作过时的信息而被拒绝
一些改进让基本算法更加健壮:
1 当一个链路状态分组到达某个路由器时,它首先被放到一个保留区中等待一段时间
2 如果来自相同路由器的另一个分组到达了,这两个分组的序列号会被比较:
如果相等,是重复分组,丢弃
如果不相等,旧的那个被丢弃
3 为了防止路由器到路由器的线路发生错误,所有的链路状态分组都要被确认
4 当一条线路空闲的时候,路由器扫描保留区,以便选择一个分组或确认,并将其发送出去
5 计算新的路由路径
一旦一个路由器获得了全部的链路状态分组就可以构造出全网络图来了(Graph)
可以使用最短路径算法来计算路由器之间最短路径
计算结果是一棵树,会形成相应的路由,安装在路由表中,引导数据分组的转发
区别


动态路由
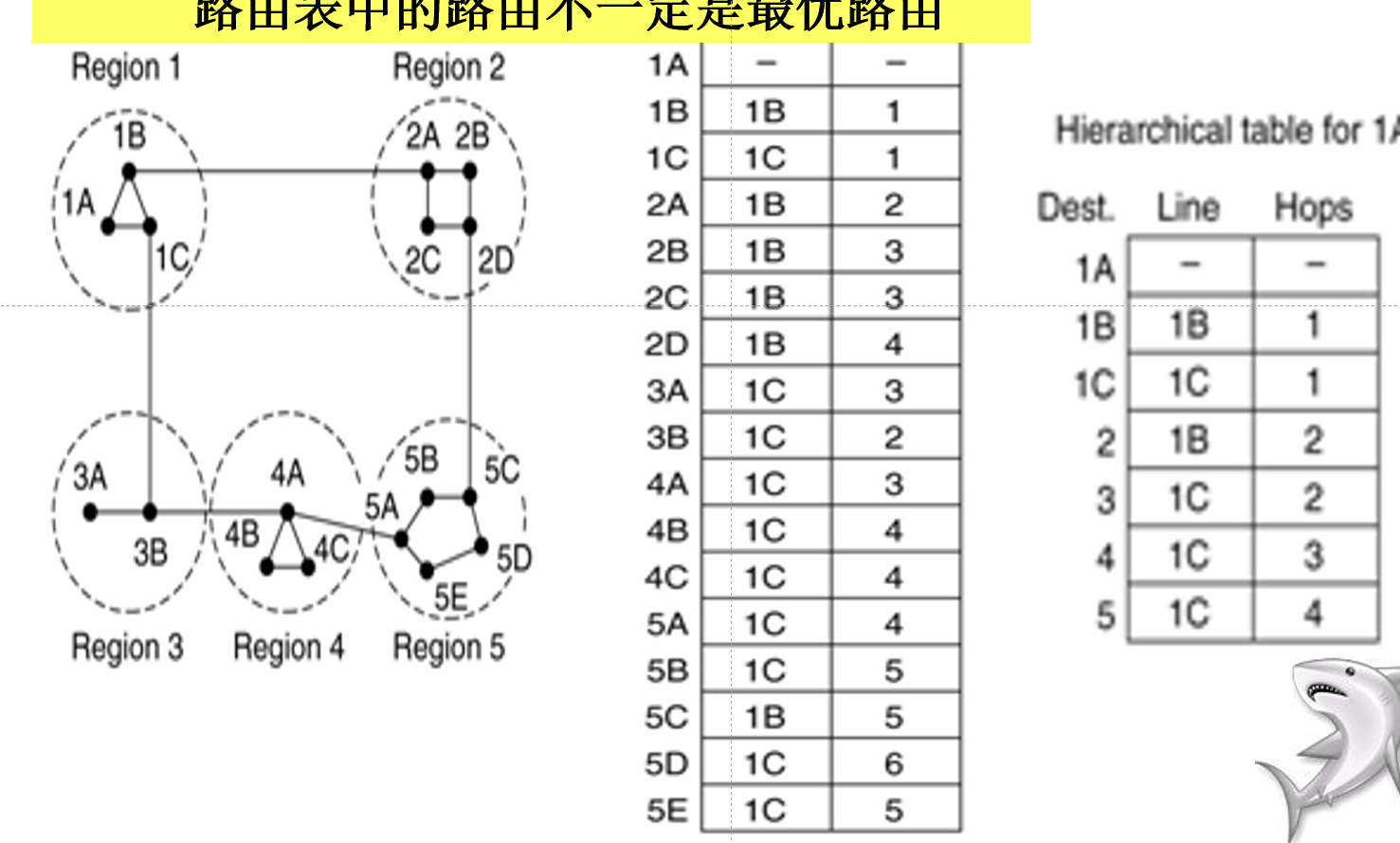
分层路由
简单来说就是分级管理,三五成坨,三坨成群。

广播路由
每个数据包发送给所有的机器
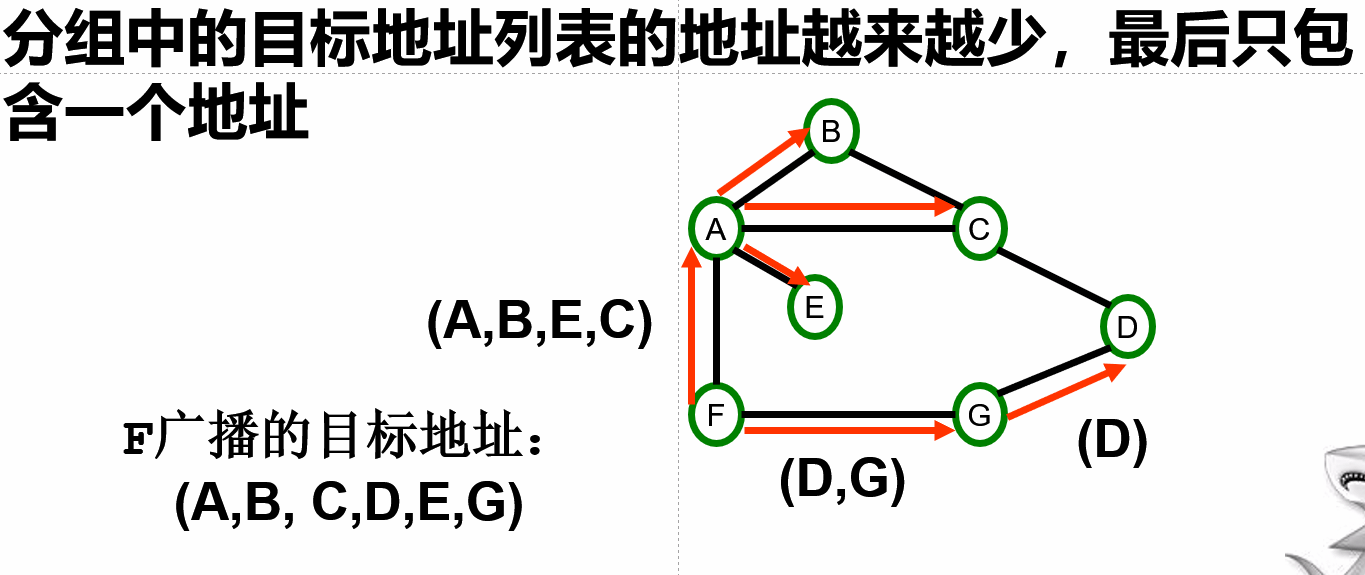
多目标路由
每个数据包包含一组目标地址
路由器检查所有的目标,将分组的副本发送到必要的链路

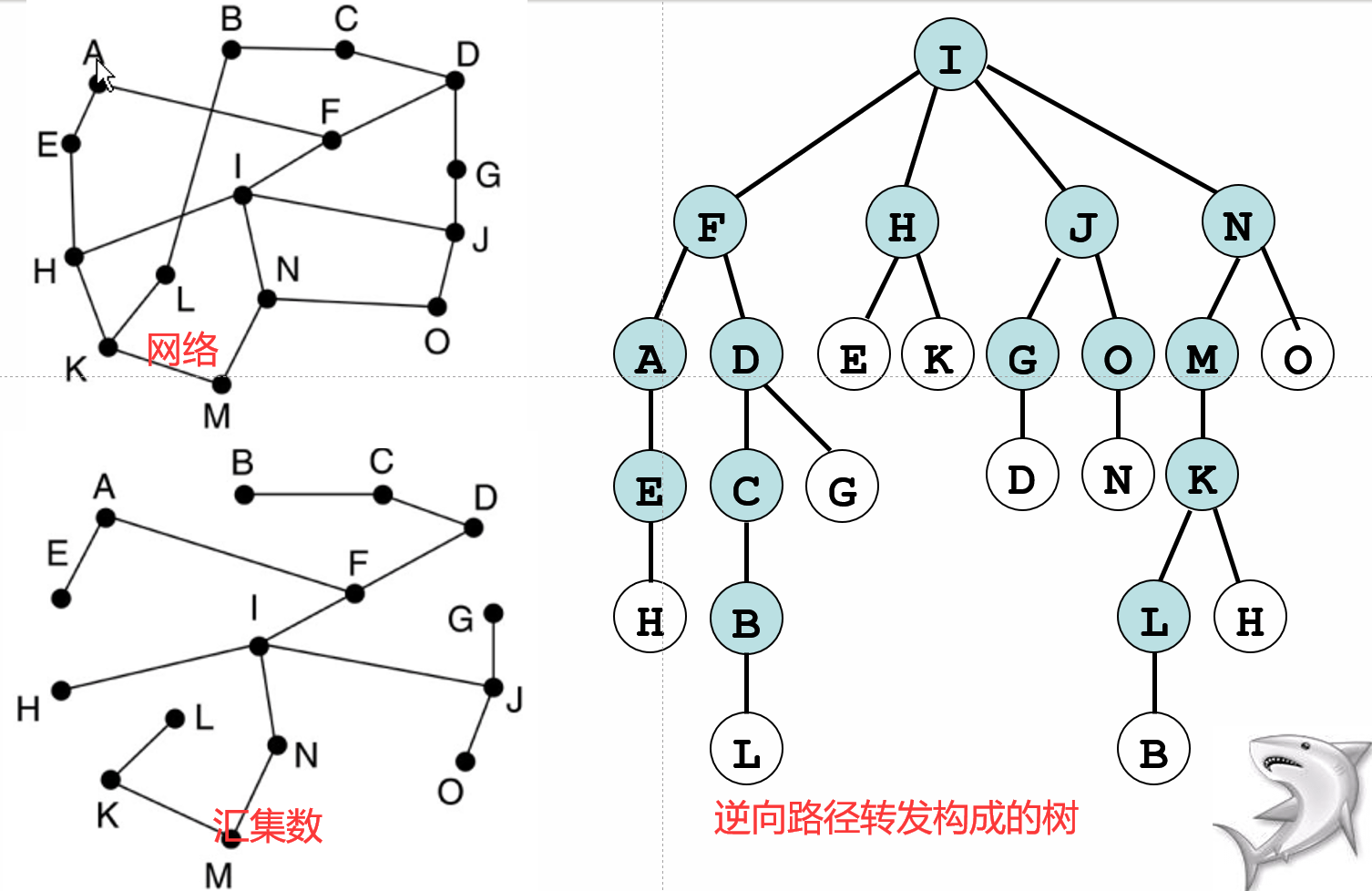
逆向路径转发
每个点先周围的结点发送(除了已经被发过的除外)类似于广搜



汇集树
就是最小生成树
总结

组播路由
选播路由
拥塞控制


流量控制路由





网际协议IP

 将整个Internet粘合在一起的是IP(Internet Protocol)
将整个Internet粘合在一起的是IP(Internet Protocol)
IP协议设计之初就考虑了网络互联的需求
-
IP的任务
提供一种尽力投递的(best-efforts,即不提供任何保证)方法将数据报从源端传输到目标端,它不关心源机器和目标机器是否在同样的网络中,也不关心它们之间是否还有其他网络
分类的IP地址
-
IP地址的问题
IPV4的数量太少


IP地址分类
为了屏蔽物理网络地址的差异,IP采用一种全局通用的地址格式为全网的每个主机和路由器分配一个唯一的地址
实际上,IP地址引用的不是一台主机,而是一个网络接口。大多数主机只有一个网络接口,也就只有一个IP地址
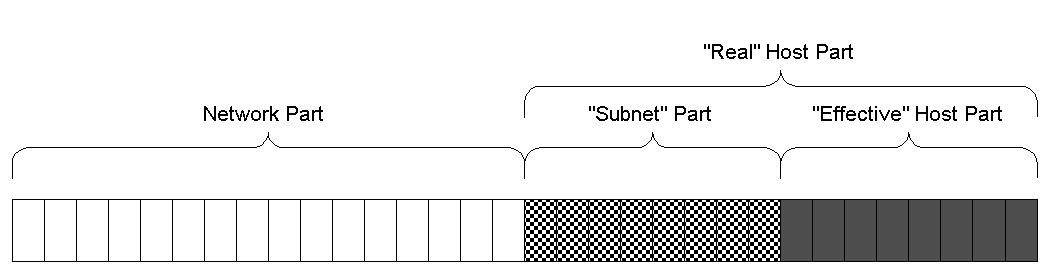
IP地址是32位长,包含网络部分和主机部分
- IP地址分类
总长度域、标识域
A类地址


Class A - 0nnnnnnn hhhhhhhh hhhhhhhh hhhhhhhh
第一位为0;7位网络位;24位主机位
第一个字节:0-127
允许多达126个网络(0和127保留)
每个网络允许多达16,777,214(=2^24-2)台主机
B类地址


Class B - 10nnnnnn nnnnnnnn hhhhhhhh hhhhhhhh
前两位10; 14位网络位;16位主机位
第一个字节:128-191
允许多达16,384(=2^14)个网络
每个网络允许多达65,534(=2^16-2)台主机
C类地址


Class C - 110nnnnn nnnnnnnn nnnnnnnn hhhhhhhh
前三位110;21位网络位;8位主机位
第一个字节:192 - 223
允许多达2,097,152网络
每个网络允许多达254台主机
D类地址


Class D - 1110mmmm mmmmmmmm mmmmmmmm mmmmmmmm
前四位1110;28位多播( multicast)地址位
第一个字节:224 - 247
D类地址是多播地址 – 见RFC 1112
E类地址


Class E - 1111rrrr rrrrrrrr rrrrrrrr rrrrrrrr
前四位1111;28位保留地址位
第一个字节:248 - 255
预留将来扩展
IP地址表示
点分十进制
161.0.116.225
二进制
10100001 00000000 01110100 11100001
十六进制
A10074E1
特殊IP地址
环回地址(Loopback)
-
每个IP协议栈都实现了
127.0.0.0
-
本地网络的广播地址和对一个指定网络的广播地址
FF.FF.FF.FF: 255.255.255.255
network.FF: 196.34.5.255, 19.255.255.255
-
网络地址
network.00: 196.34.5.0
-
本地网络中的主机地址
00.00.00.host: 0.0.0.188
IP地址管理
IP地址公共互联网的地址号由ISP分配
IP地址方案的缺点


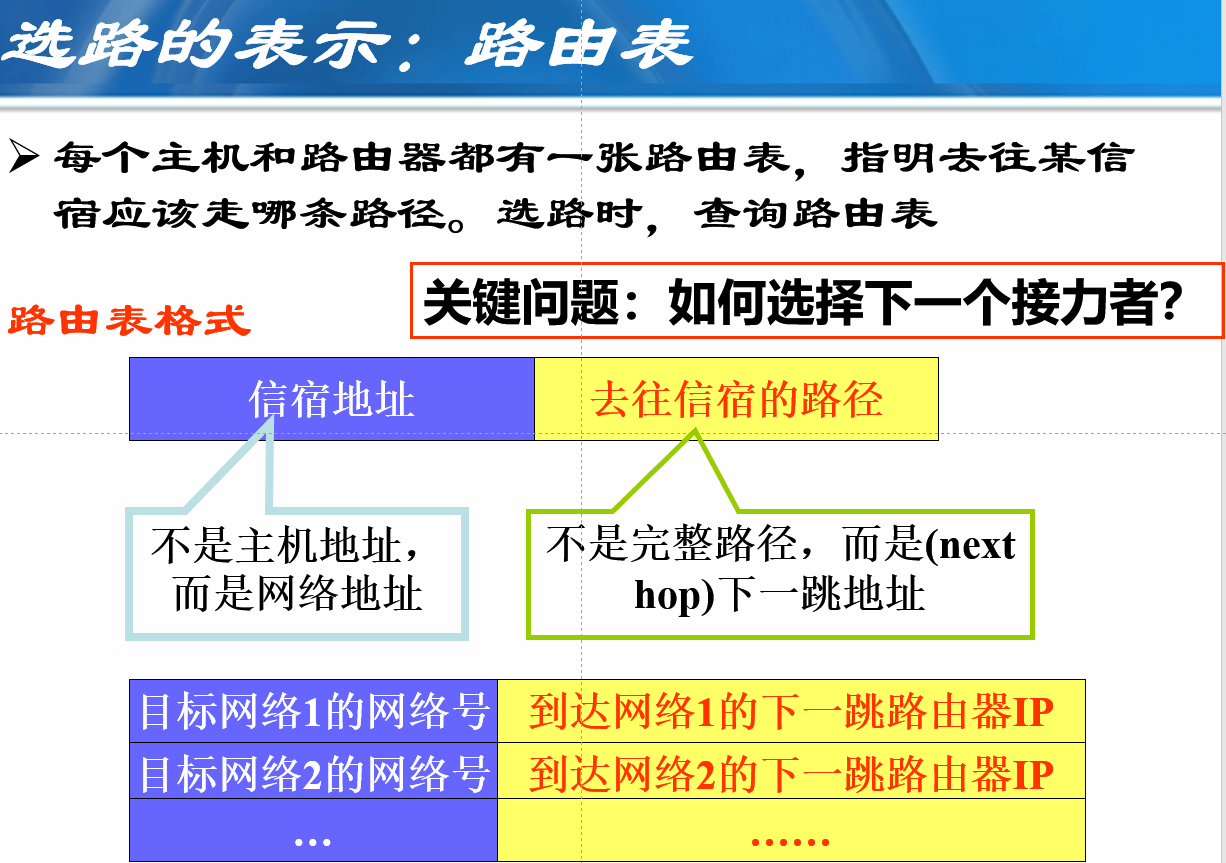
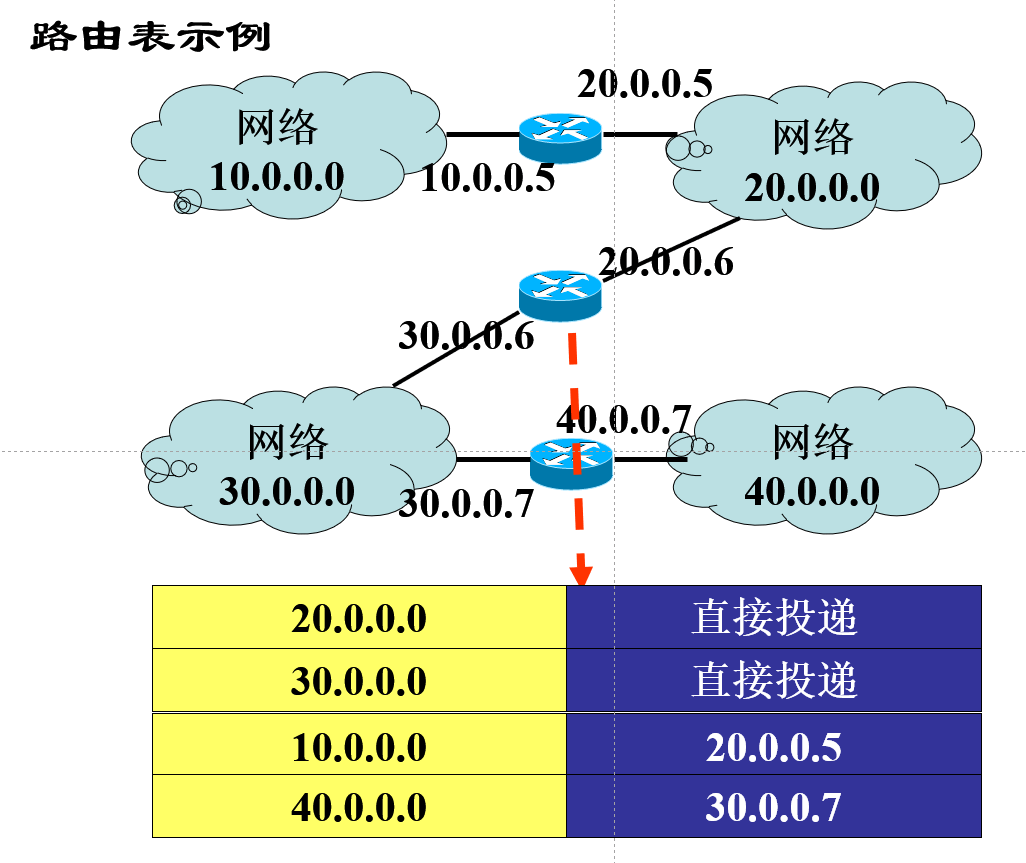
选路与转发
路由器主要完成两个功能:是路由选择 (确定哪一 条路径),二是分组转发 (当一个分组 到达时所采取的动作)。
1)路由选择。指按照复杂的分布式算法,根据从各相邻路由器所得到的关于整个网络拓扑
的变化情况,动态地改变所选择的路由。
2)分组转发。指路由器根据转发表将用户的IP数据报从合适的端口转发出去。
路由表是根据路由选择算法得出的,而转发表是从路由表得出的。
路由表则需要对网络拓扑变化的计算最优化,转发表的结构应当使查找过程最优化。
在讨论路由选择的原理时,往往不去区分转发表和路由表,而是笼统地使用路由表一词。




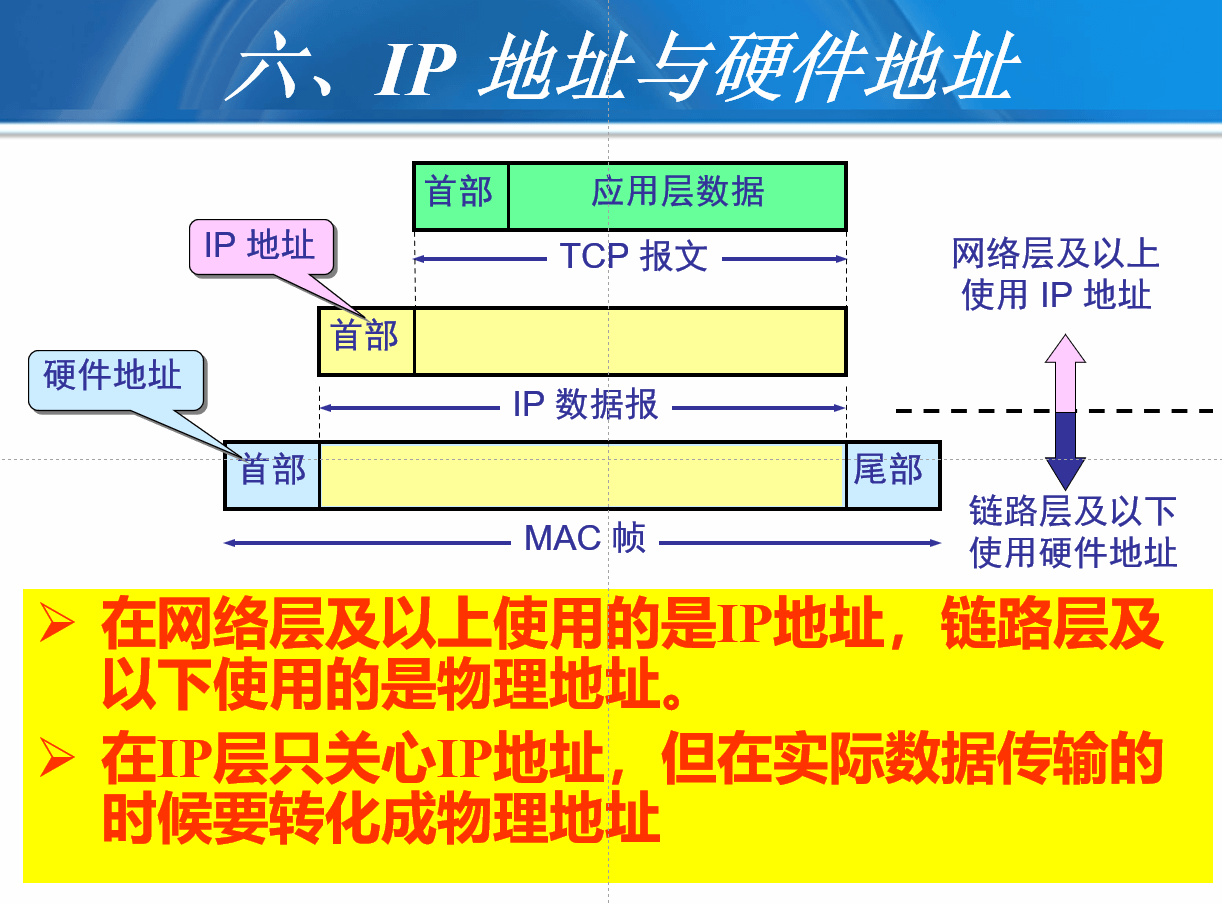
IP与硬件地址
- 在网络层及以上使用的是IP地址,链路层及以下使用的是物理地址。
-
在IP层只关心IP地址,但在实际数据传输的时候要转化成物理地址


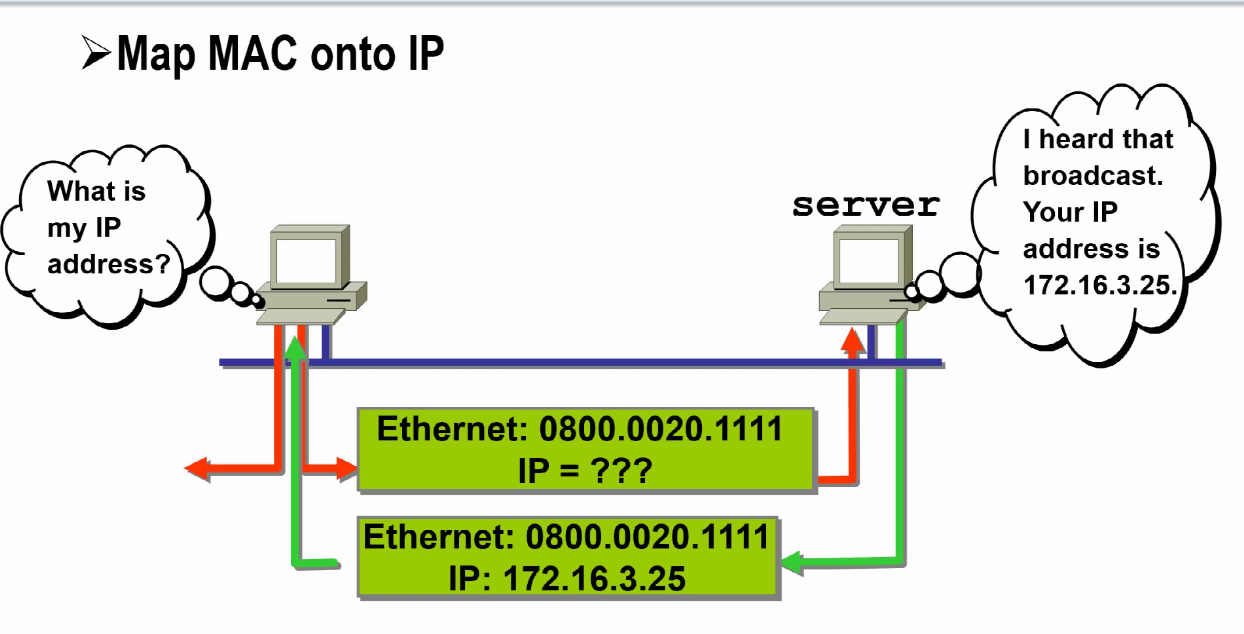
ARP协议
问题提出
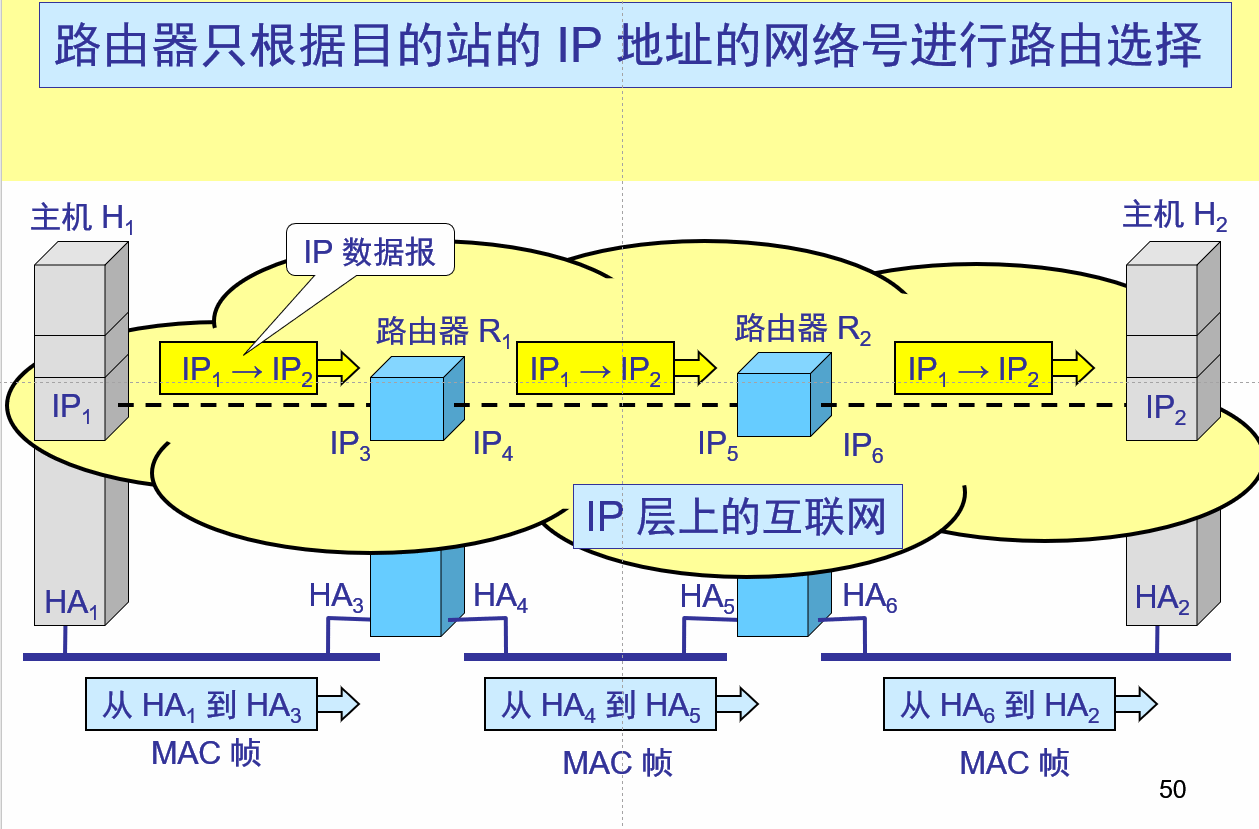
因特网上主机间通信使用的是IP地址
当一台主机发送数据包时,是根据硬件地址(如:以太网地址)来确定目的接口的
如何将IP地址映射到对应的硬件地址?
通过直接映射解析
ARP
ARP(地址解析协议)
用于在以太网中解决网络层地址(IP地址)与数据链路层地址(MAC地址)的映射问题

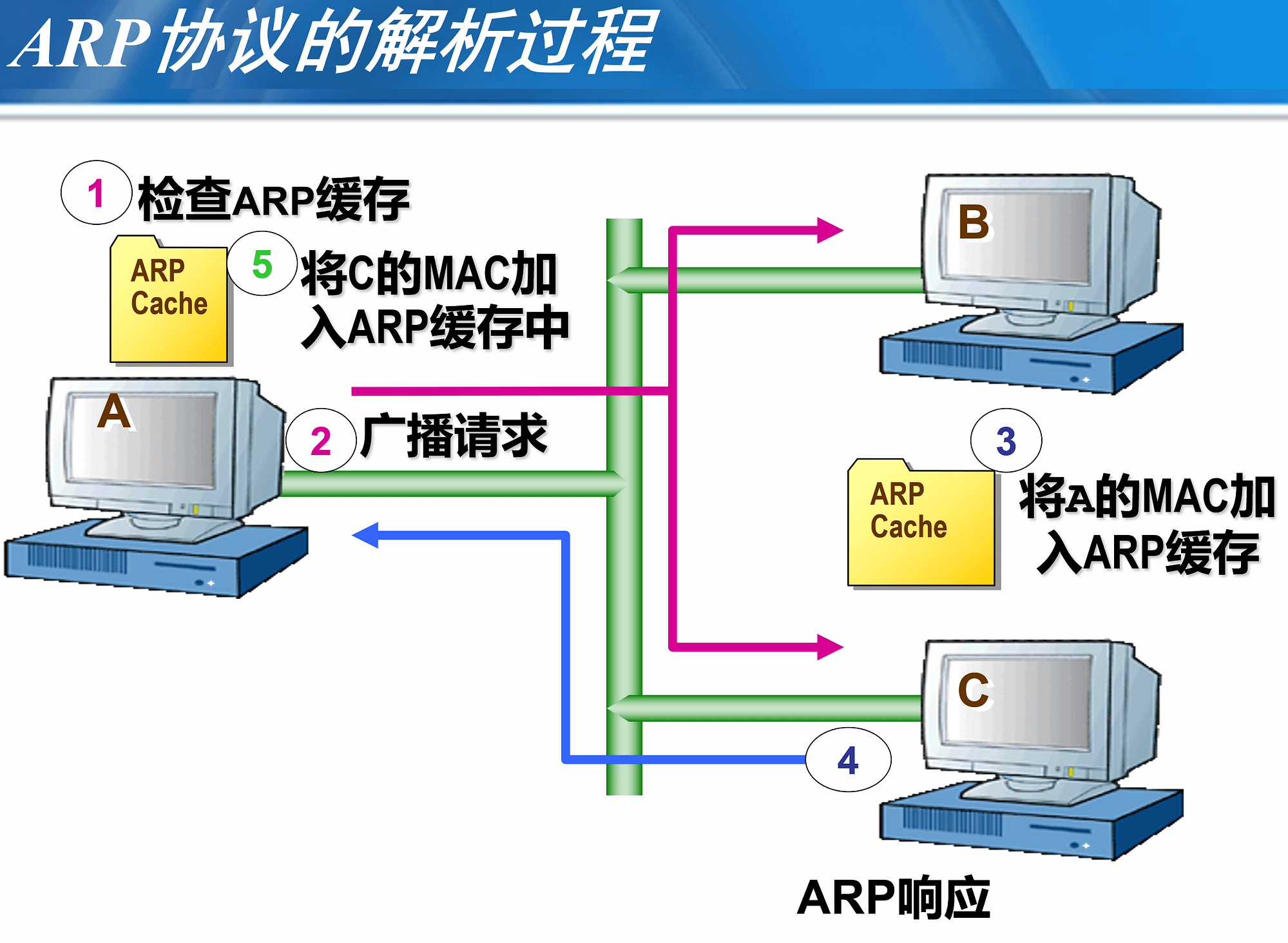

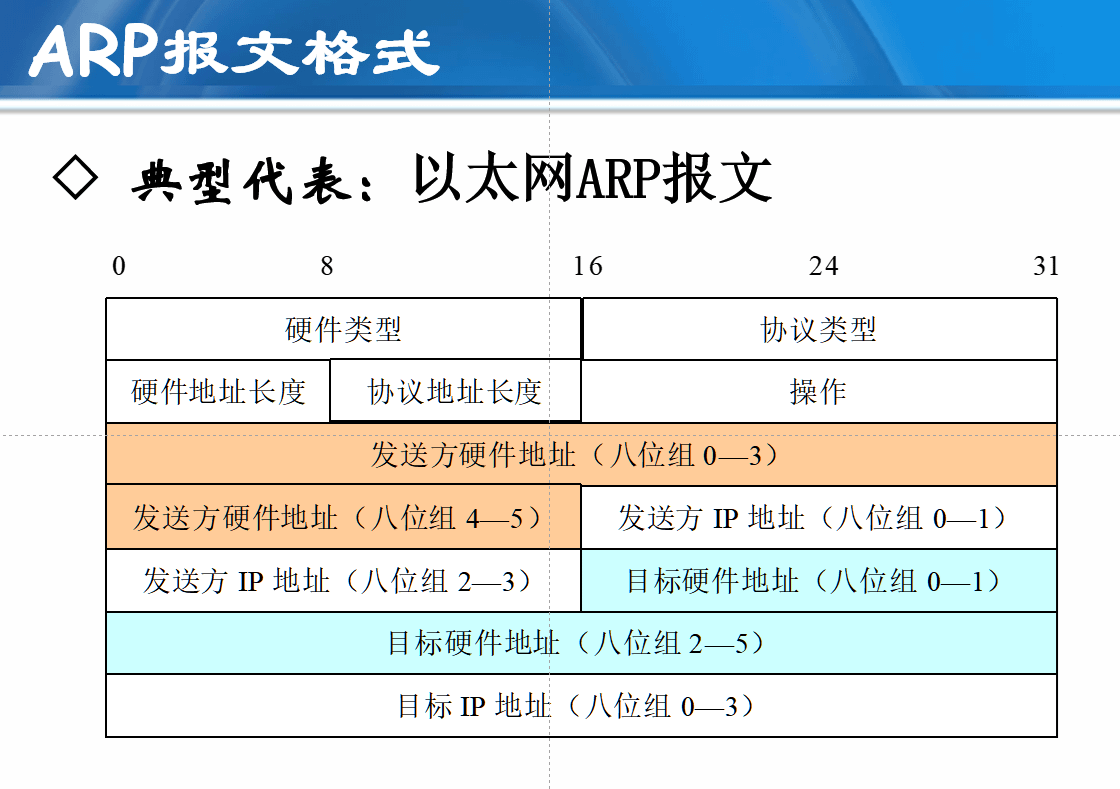 地址解析过程举例
地址解析过程举例
1.主机A发送一个广播数据包到以太网上,问“谁拥有IP地址202.112.10.5?”
2.该数据包将会到达以太网202.112.10.0/24上的每一台主机,每台主机都会检查它自己的IP地址
3.只有主机B(IP地址为202.112.10.5)会用自己的以太网地址作为应答
4.主机A收到ARP应答后,提取其中的MAC地址,进行通信
**总的来说:广播请求,单波应答**

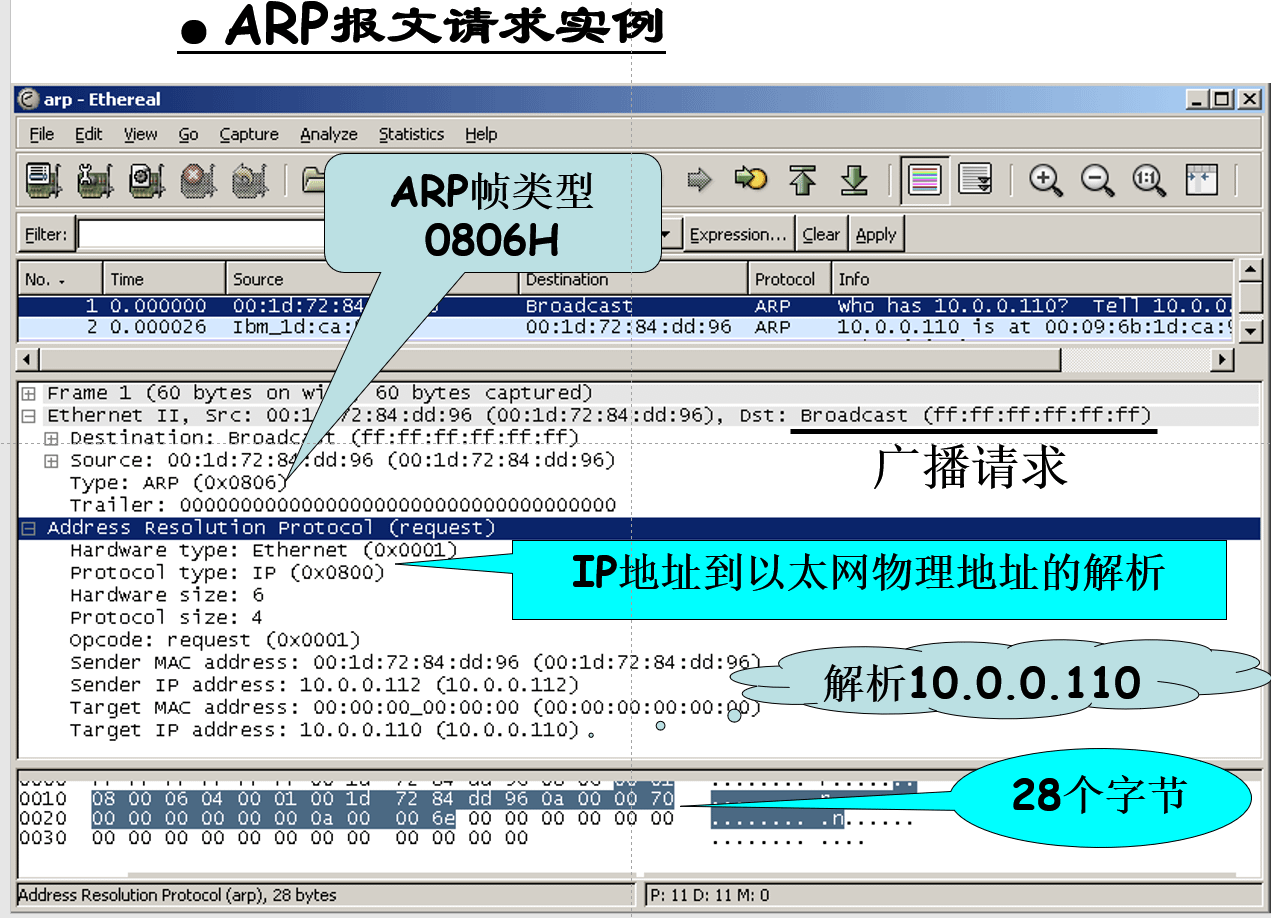

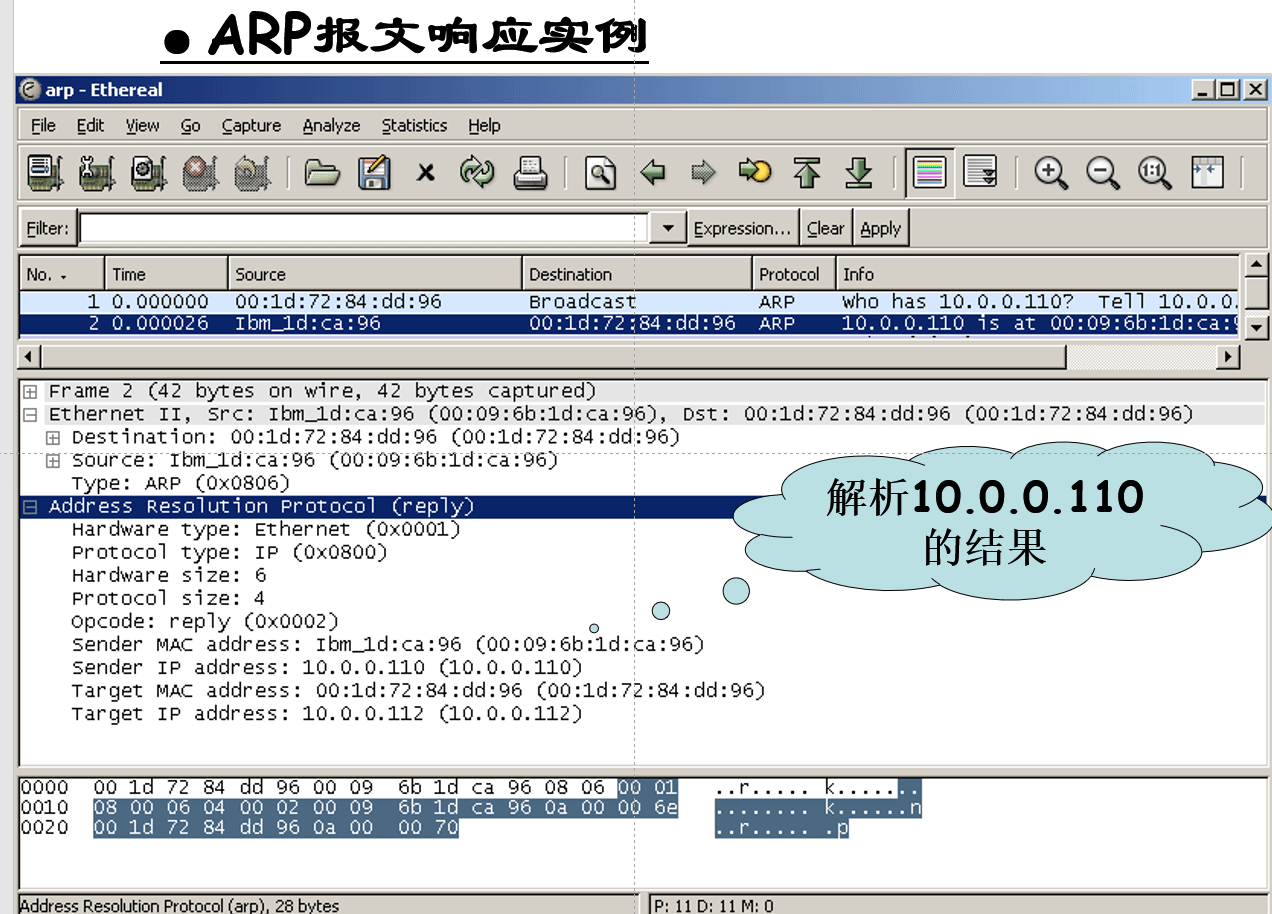
- 优化方法-ARP高速缓存
缓存IP地址和MAC地址的映射关系
减少了广播流量
缓存的映射表项要设置生存时间
一般为20分钟
ARP缓存表不要太大
-
RARP逆向寻址
如果我知道我的MAC,怎么才能知道我对应的IP呢

分类IP地址的问题
划分子网
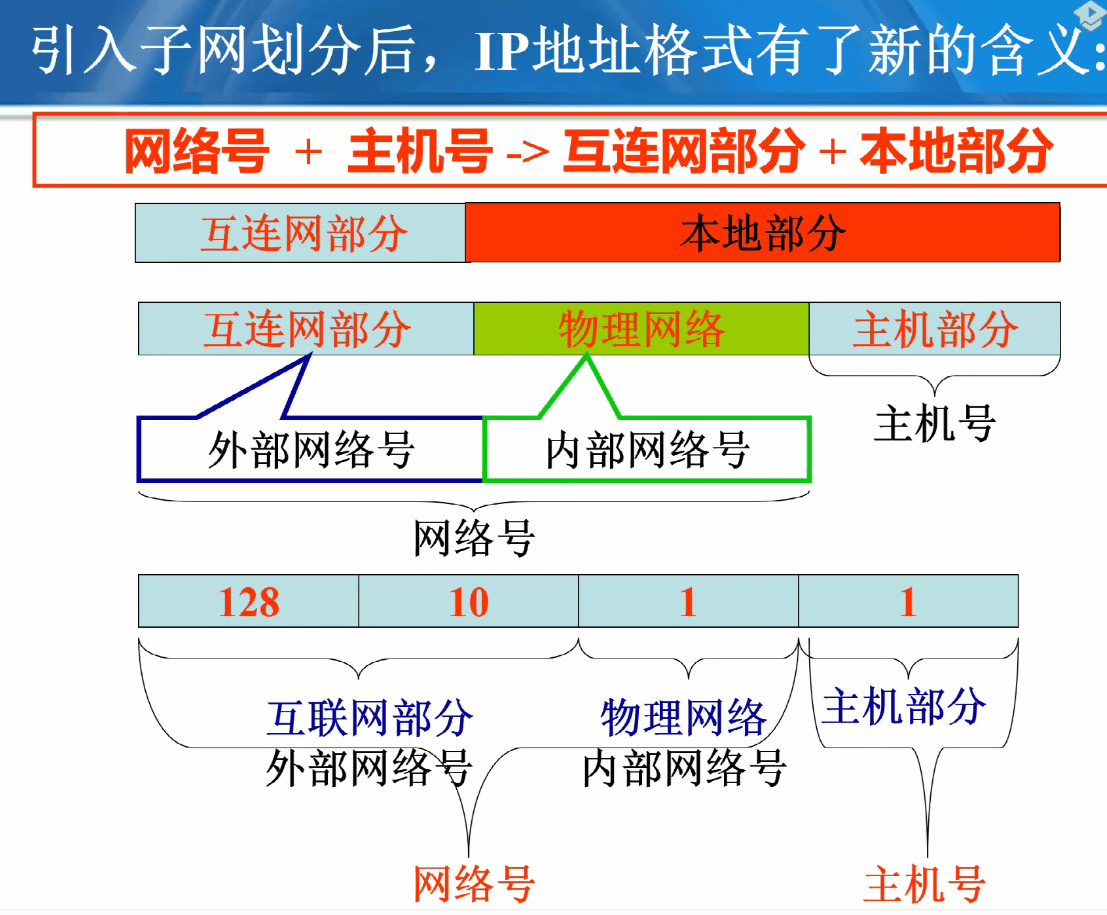
子网划分
-
为什么要进行子网划分?
- 分类地址适用于设计之初的互联网,但是A类网络和B类网络太大,不易管理
-
解决方法
-
将网络分成若干供内部使用的子网,对外界,该网络还是一个单独的网络
-

例子:

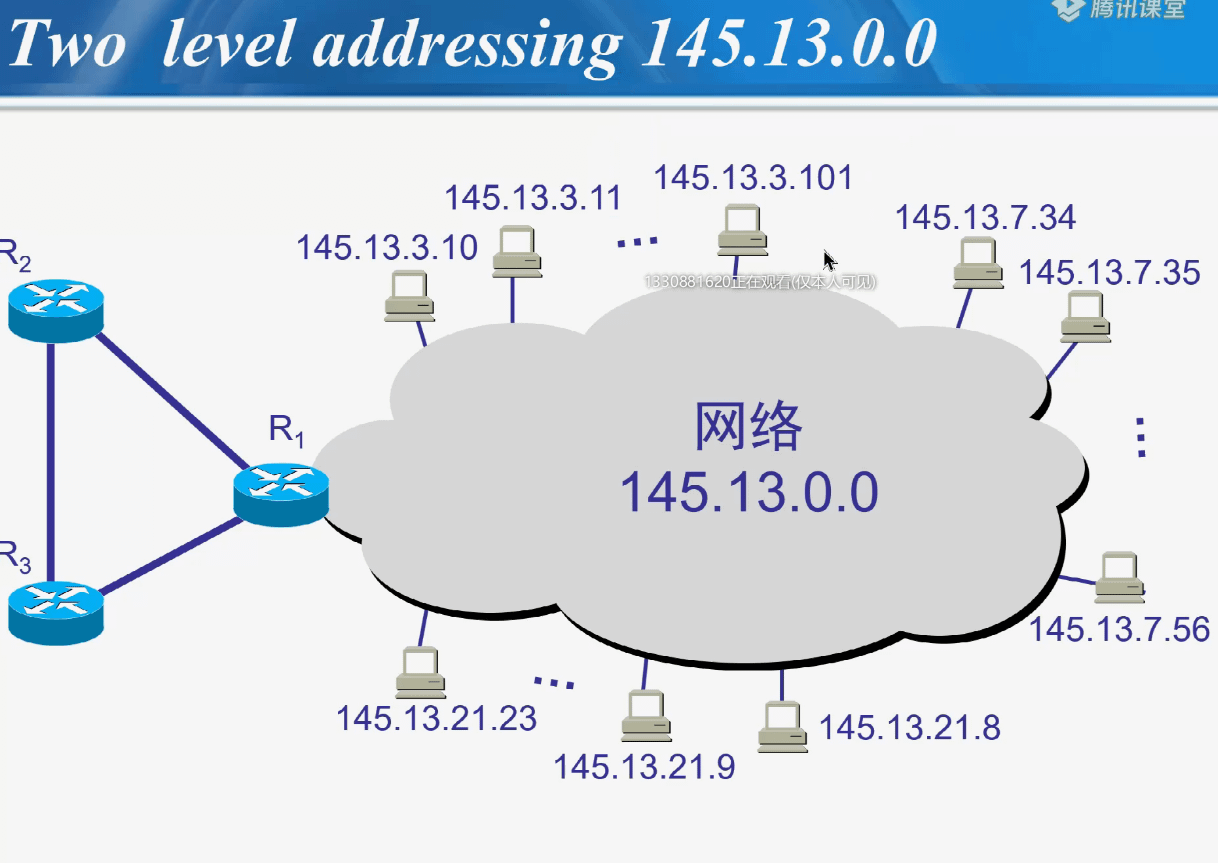

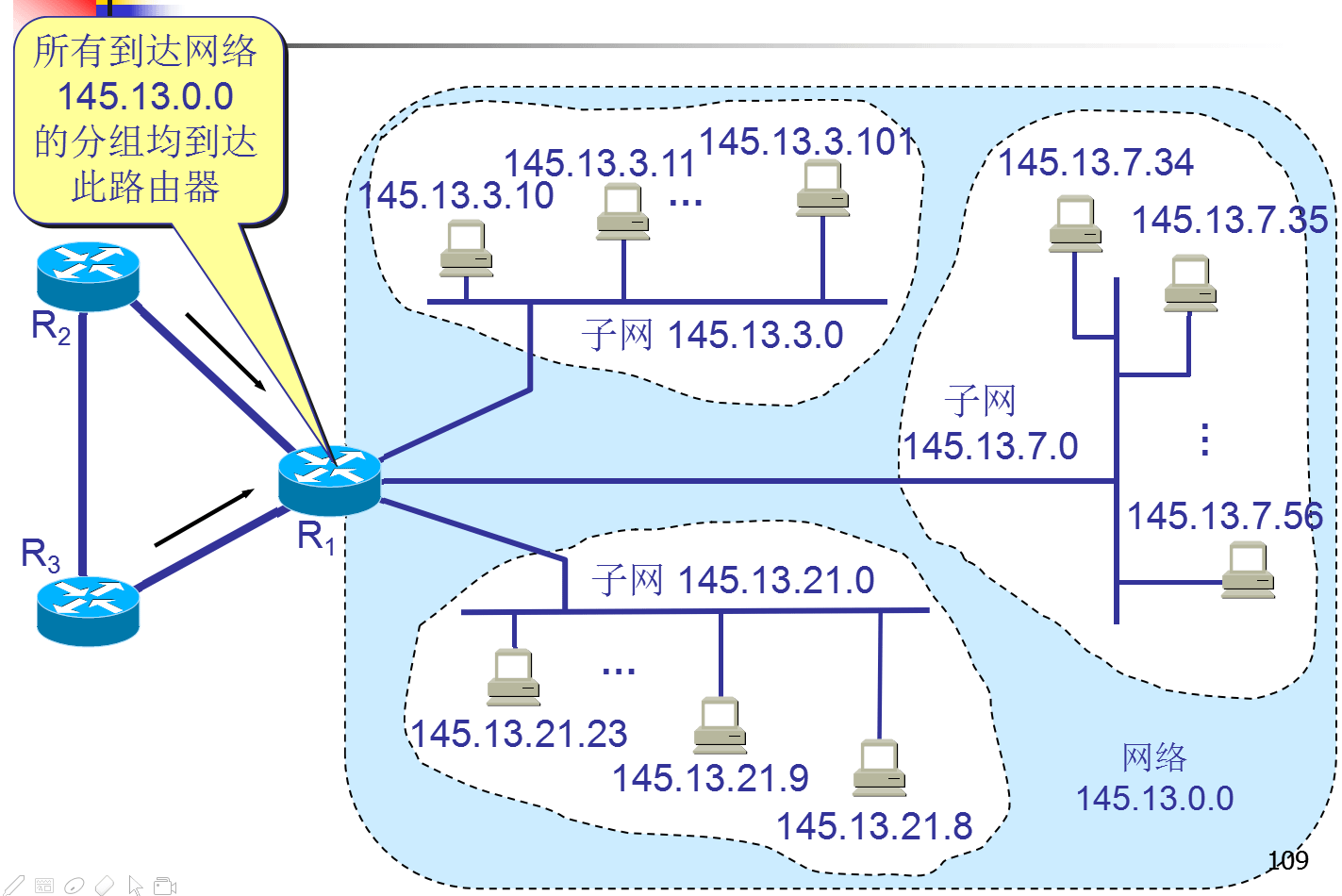
划分为三个子网后对外仍是一个网络
子网划分距离:
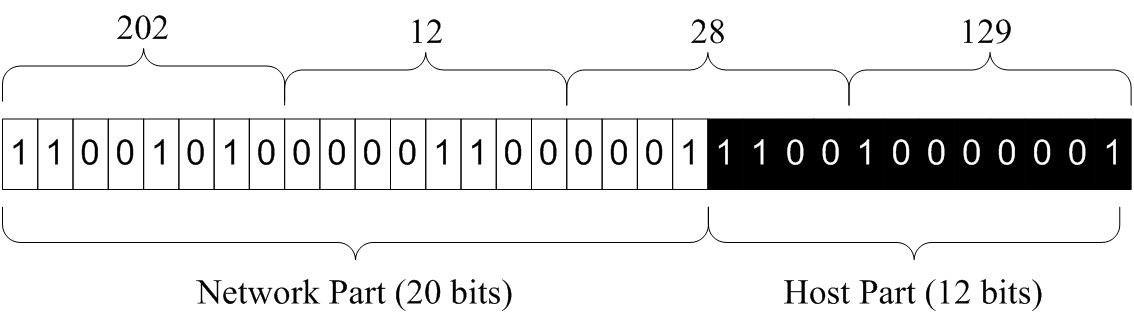
例如:C类网络192.10.1.0,主机号部分的前三位用于标识子网号,即:


子网地址分别为
11000000 00001010 00000001 00000000 -- 192.10.1.0
11000000 00001010 00000001 00100000 -- 192.10.1.32
11000000 00001010 00000001 01000000 -- 192.10.1.64
11000000 00001010 00000001 01100000 -- 192.10.1.96
11000000 00001010 00000001 10000000 -- 192.10.1.128
11000000 00001010 00000001 10100000 -- 192.10.1.160
11000000 00001010 00000001 11000000 -- 192.10.1.192
11000000 00001010 00000001 11100000 -- 192.10.1.224
子网掩码
经过上述子网划分后存在的问题,如何知道一个IP地址中哪些位是网络号+子网号,哪些位是主机号呢?
解决方法:引入子网掩码
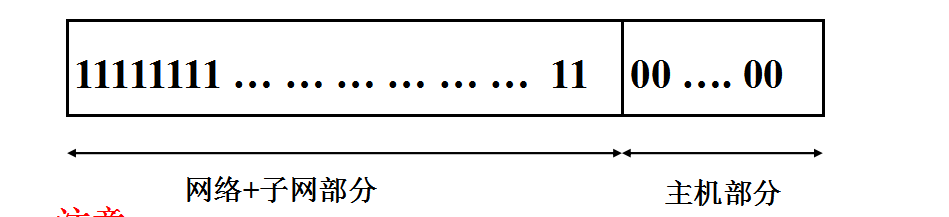
子网掩码格式:

32比特
前一部分全1,1的个数表示相应IP地址中网络+子网部分的位数
后一部分全0,0的个数表示相应IP地址中主机部分的位数
-
注意
连接在同一个子网上的所有主机和路由器的子网掩码相同
两个IP地址和子网掩码相与结果相同,表示这两个IP地址的主机在同一个子网中




构造超网
无类别域间路由(CIDR)
分类地址存在的问题:
A类、 B类地址太大
一个A类网络有16M个地址
一个B类网络有65536主机地址
C类地址太小
一个C类网络有256个地址
需要更灵活的方式!
解决方法1:子网划分
将网络分成若干供内部使用的子网

但是还存在着问题
C类地址太小
每个C类网络对应一个路由表项,造成路由表膨胀
解决方法2:CIDR
在网络和主机间使用可变长度的划分方法,即无类别地址(CIDR),不需要子网

表示法:
点分十进制表示法后跟“/”和网络部分长度
如:198.16.16.0/21
198.16.16.0/21表示网络部分长度为21的一段地址,这段地址中第一个地址为198.16.16.0,最后一个地址为198.16.23.255
使用CIDR需要路由协议的支持(到目前所有路由器都支持)


每个路由表项进行扩展,增加了32位的掩码。路由表由所有网络的三元组(IP地址、子网掩码、输出线路)构成的
当一个数据包到达时,路由器首先将它的目标IP提取出来,和子网掩码去“与”,结果和表项中的网络号比较,是否匹配
最长匹配原则
路由查找时,若多个路由表项匹配成功,选择掩码长(1比特数多)的路由表项
网络地址转换NAT



一、NAT 概述
NAT 是将 IP 数据报报头中的 IP 地址转换为另一个 IP 地址的过程,主要用于实现内部网络(私有 IP 地址)访问外部网络(公有 IP 地址)的功能。Basic NAT 是实现一对一的 IP 地址转换,而 NAPT 可以实现多个私有地址映射到同一个公有地址上。Basic NAT
Basic NAT 方式属于一对一的地址转换,在这种方式下只转换 IP 地址,而对 TCP/UDP 协议的端口号不处理,一个公网 IP 地址不能同时被多个用户使用。
Basic NAT 示意图

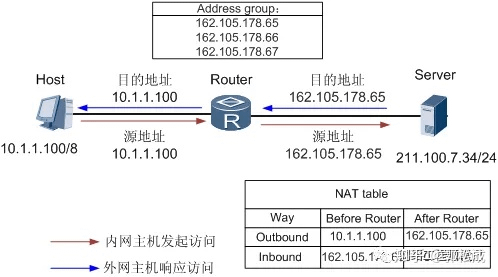
图描述了 Basic NAT 的基本原理,处理过程如下:
- Router 收到内网侧 Host 发送的访问公网侧 Server 的报文,其源 IP 地址为 10.1.1.100。
-
Router 从地址池中选取一个空闲的公网 IP 地址,建立与内网侧报文源 IP 地址间的 NAT 转换表项(正反向),并依据查找正向 NAT 表项的结果将报文转换后向公网侧发送,其源 IP 地址是 162.105.178.65,目的 IP 地址是 211.100.7.34。3.Router 收到公网侧的回应报文后,根据其目的 IP 地址查找反向 NAT 表项,并依据查表结果将报文转换后向私网侧发送,其源 IP 地址是 162.105.178.65,目的 IP 地址是 10.1.1.100。说明:
由于 Basic NAT 这种一对一的转换方式并未实现公网地址的复用,不能有效解决 IP 地址短缺的问题,因此在实际应用中并不常用。
NAT 服务器拥有的公有 IP 地址数目要远少于内部网络的主机数目,这是因为所有内部主机并不会同时访问外部网络。公有 IP 地址数目的确定,应根据网络高峰期可能访问外部网络的内部主机数目的统计值来确定。NAPT
除一对一的 NAT 转换方式外,网络地址端口转换 NAPT(Network Address Port Translation)可以实现并发的地址转换。它允许多个内部地址映射到同一个公有地址上,因此也可以称为“多对一地址转换”或地址复用。
NAPT 方式属于多对一的地址转换,它通过使用“IP 地址+端口号”的形式进行转换,使多个私网用户可共用一个公网 IP 地址访问外网。
NAPT 示意图

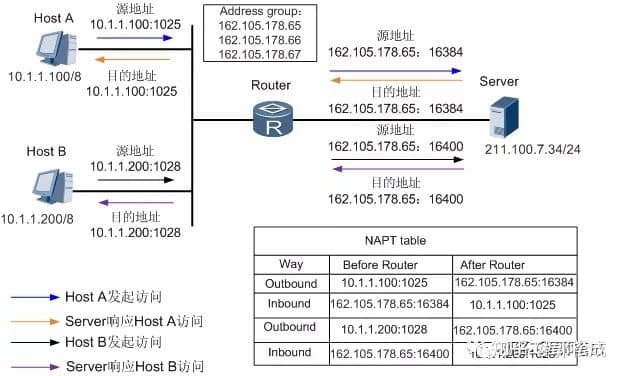
如图所示, NAPT 方式的处理过程如下:
- Router 收到内网侧 Host 发送的访问公网侧 Server 的报文。比如收到 Host A 报文的源地址是 10.1.1.100,端口号 1025。
- Router 从地址池中选取一对空闲的“公网 IP 地址+端口号”,建立与内网侧报文“源 IP 地址+源端口号”间的 NAPT 转换表项(正反向),并依据查找正向 NAPT 表项的结果将报文转换后向公网侧发送。比如Host A 的报文经 Router 转换后的报文源地址为 162.105.178.65,端口号 16384。3.Router 收到公网侧的回应报文后,根据其“目的 IP 地址+目的端口号”查找反向 NAPT 表项,并依据查表结果将报文转换后向私网侧发送。比如Server回应Host A的报文经Router转换后,目的地址为10.1.1.100,端口号 1025。
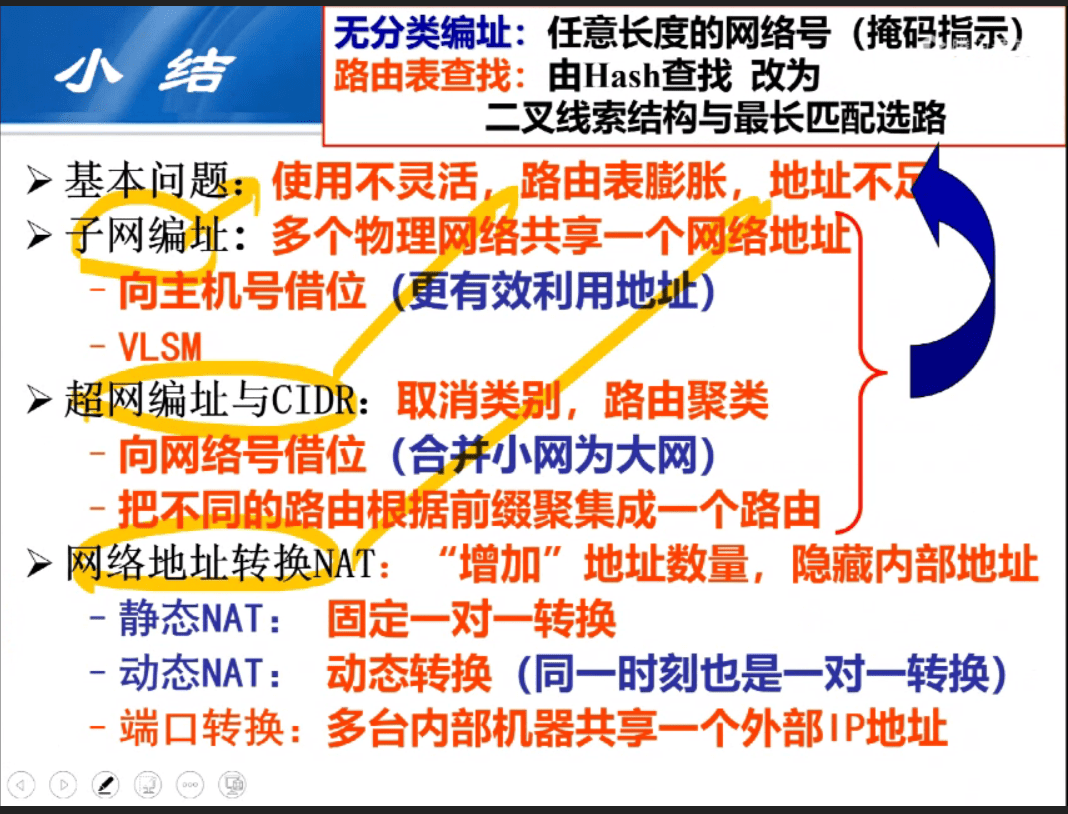
小结

互联网协议IP
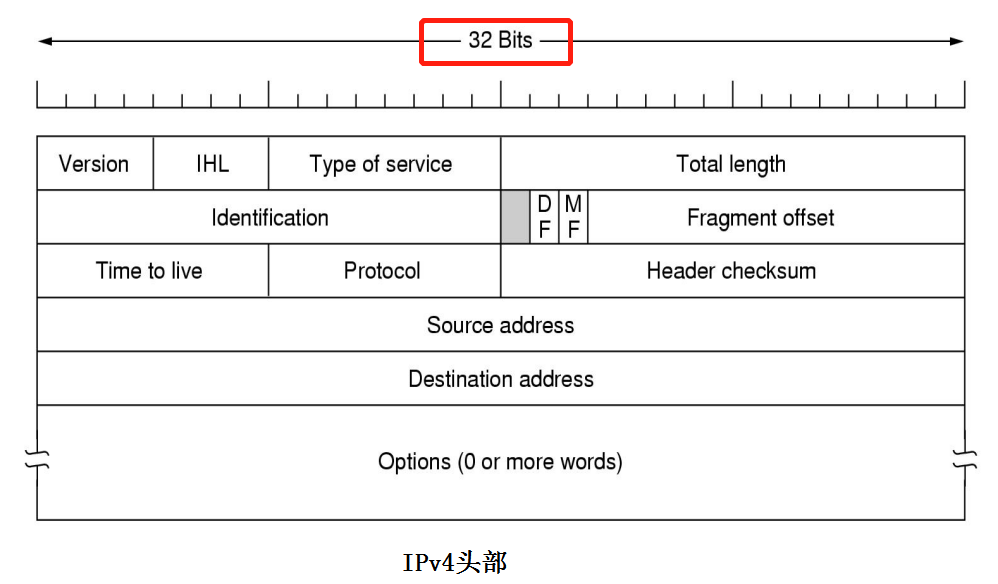
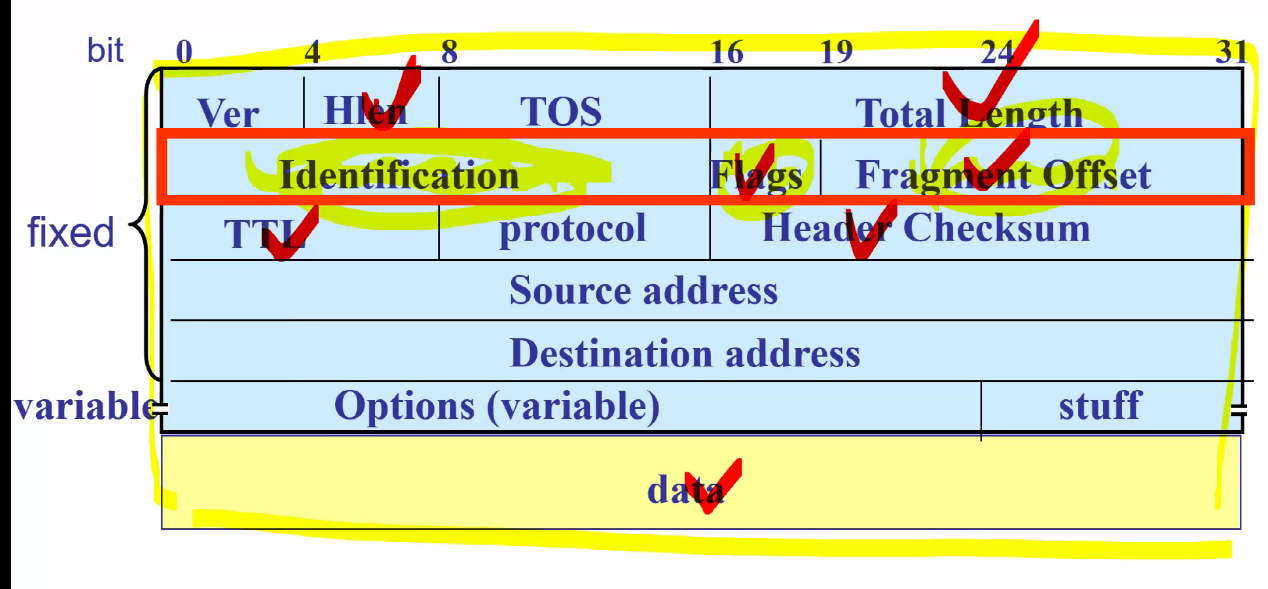
IPv4协议包
IPv4协议头部的各个字段信息


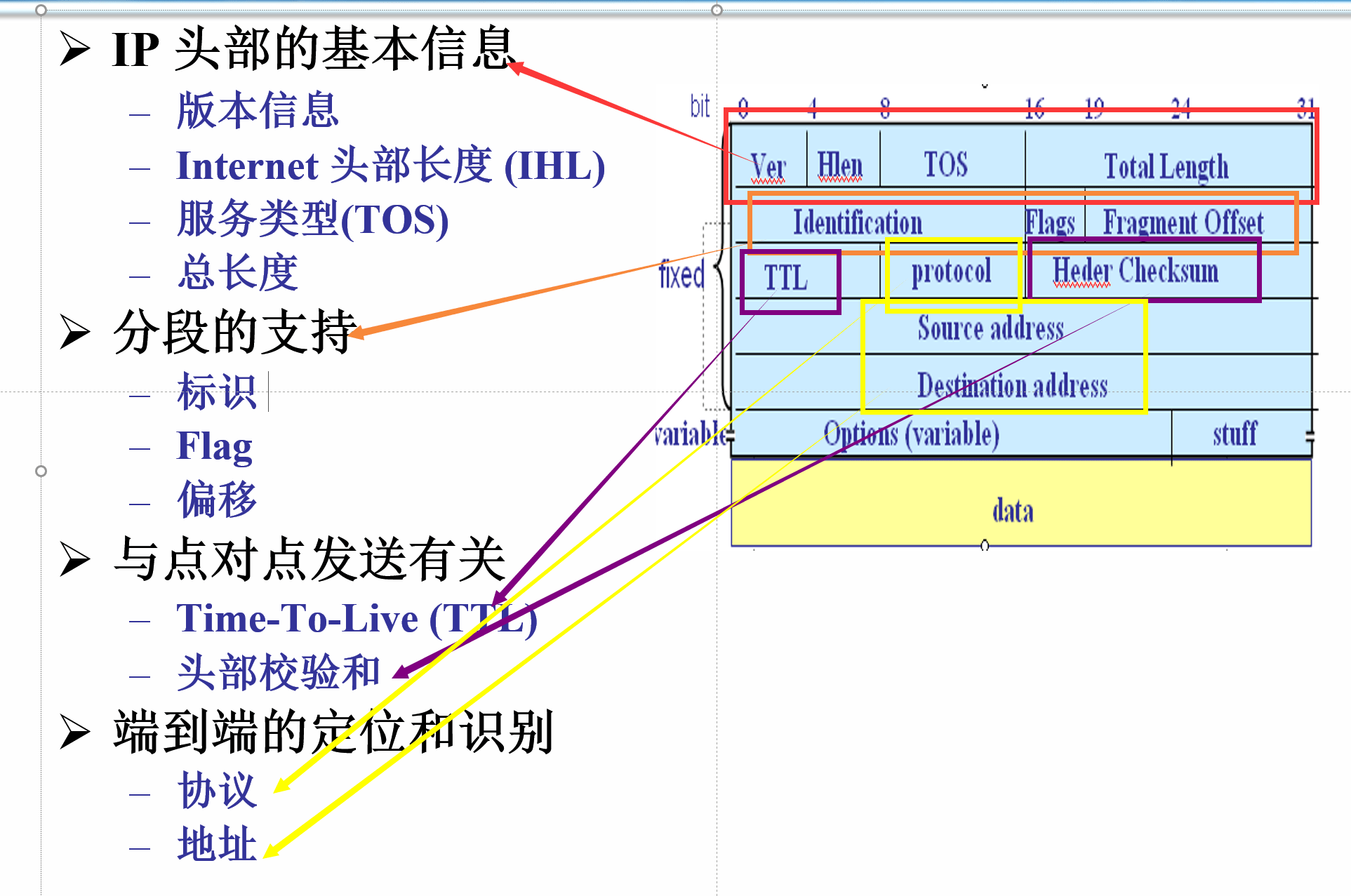
各个字段的含义:
-
版本号(version)
4bits,IPv4协议填4,IPv6协议填6 -
头部长度(IHL)
4bits,单位为4字节,取值范围5-15(确省值为5,即标准头标长20字节),指示IP包头的长度 -
服务类型(TOS)域
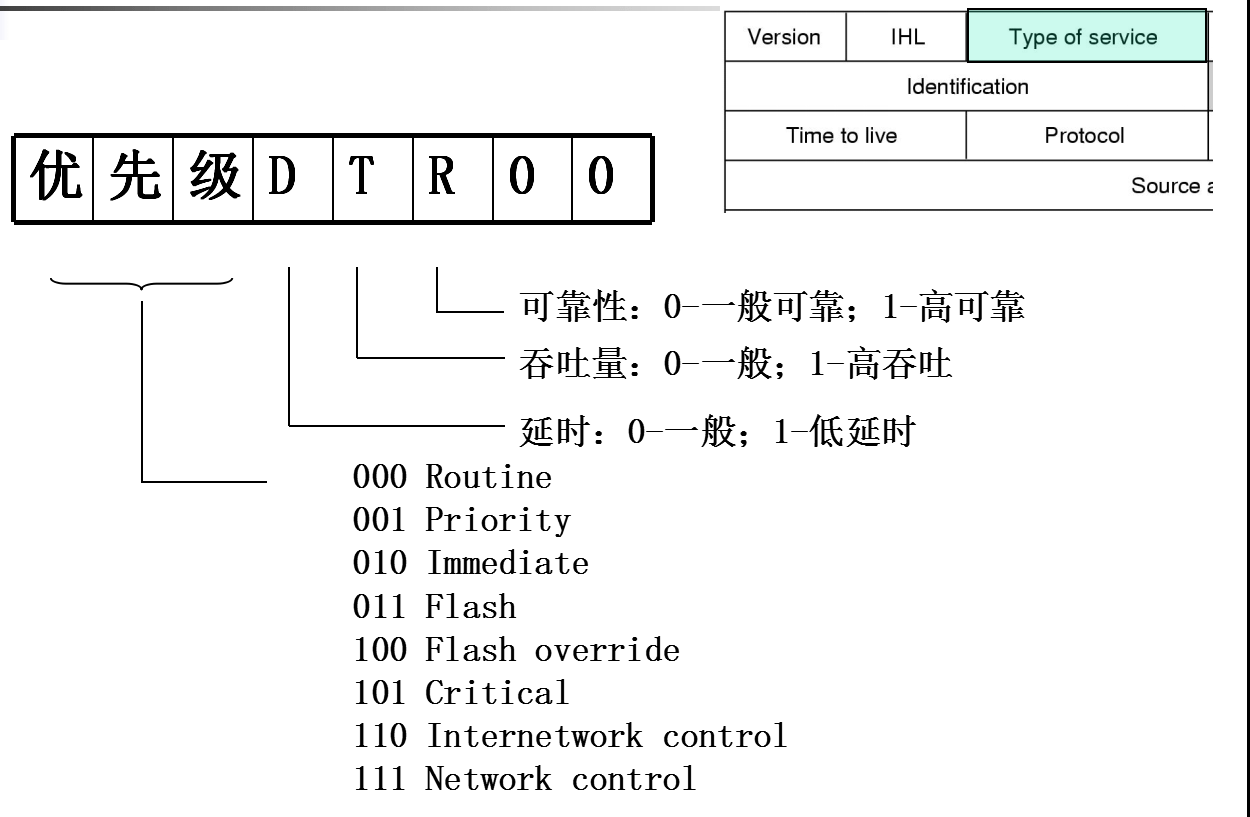
-
总长度域、标识域
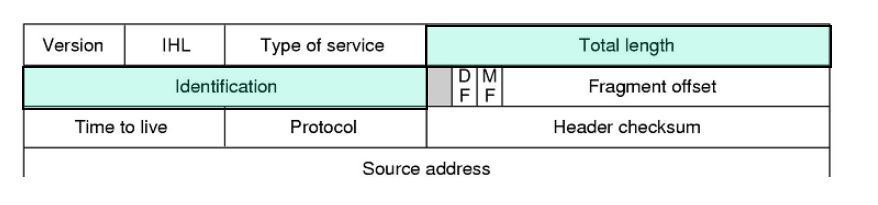
-
总长度域
16bits ,单位字节,描述IP包的总长(包括头和数据),最大包长度为65535字节 -
标识域
16bits,用于唯一标识该包
-
-
标志域、分段偏移域
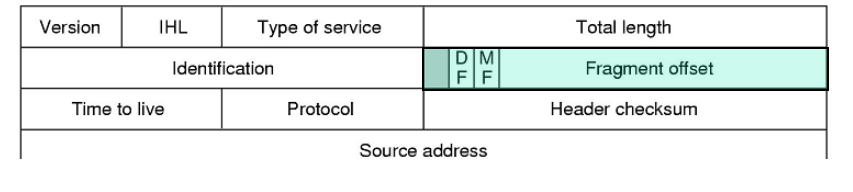
-
标志域
3bits。第1位未定义
第2位DF代表“不分段”,DF为0表示该包可分段,否则表示不可分段
第3位MF代表“更多的分段”,MF为0表示这是最后分段,否则表示还有后续分段 -
分段偏移域
13bits,单位8字节。取值0-8191,标明当前报片在原包中的位置
-
-
生存时间域、协议域
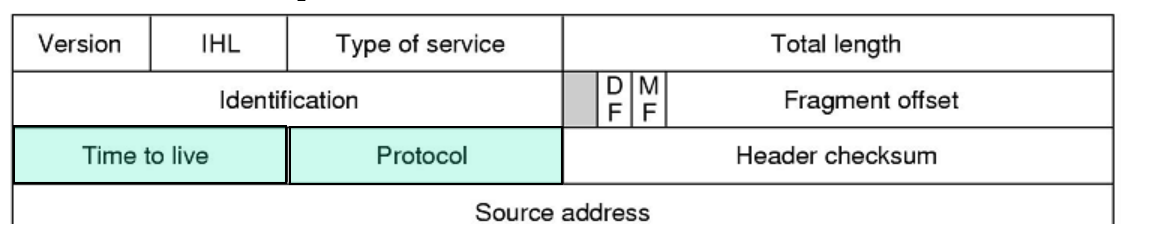
-
生存时间(TTL)域
8bits,单位秒,表示包的生存时间。实际操作时,包每经过一个路由器,TTL值减一,当TTL值为0时,该包被丢弃 -
协议(Protocol)域
表示高层协议类型。协议的编号详见http://www.iana.org
0 Reserved
1 Internet Control Message Protocol (ICMP)
2 Internet Group Management Protocol (IGMP)
3 Gateway-to-Gateway Protocol (GGP)
4 IP (IP encapsulation)
5 Stream
6 Transmission Control (TCP)
8 Exterior Gateway Protocol (EGP)
9 Private Interior Routing Protocol
17 User Datagram (UDP)
-
-
头部校验和域、源/目的地址域

-
头部校验和域
16bits,用来检验包头 -
源地址域
32bits,包的发送者的IP地址 -
目的地址域
32bits,包的接收者的IP地址 -
填充(padding)
包头长度必须为4字节的整数倍,如果选项的长度不是4字节的整数倍,那么就要进行填充
-
-
选项(option)


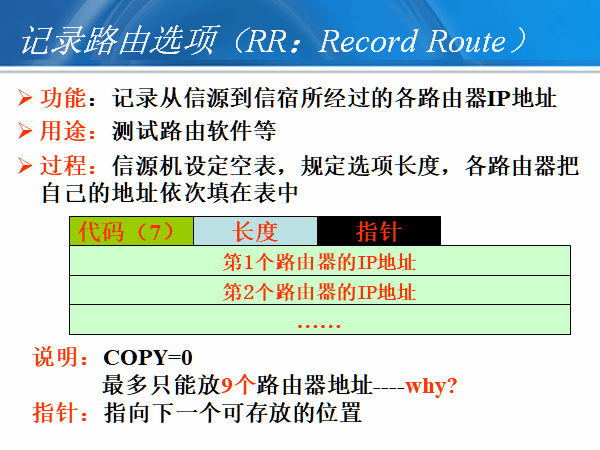














IP包分片
-
分片首部需要做哪些修改?



-
如何重组分片?

-
何处重组分片?





互联网的路由选择协议
Internet中的自治系统结构
-
问题:
- Internet规模越来越大
- 许多单位不愿意公开自己的网络布局,有希望连接Internet
-
解决:分布式资源管理
-
两级路由结构
- 域内:在同一控制域
- 域间:在不同控制域

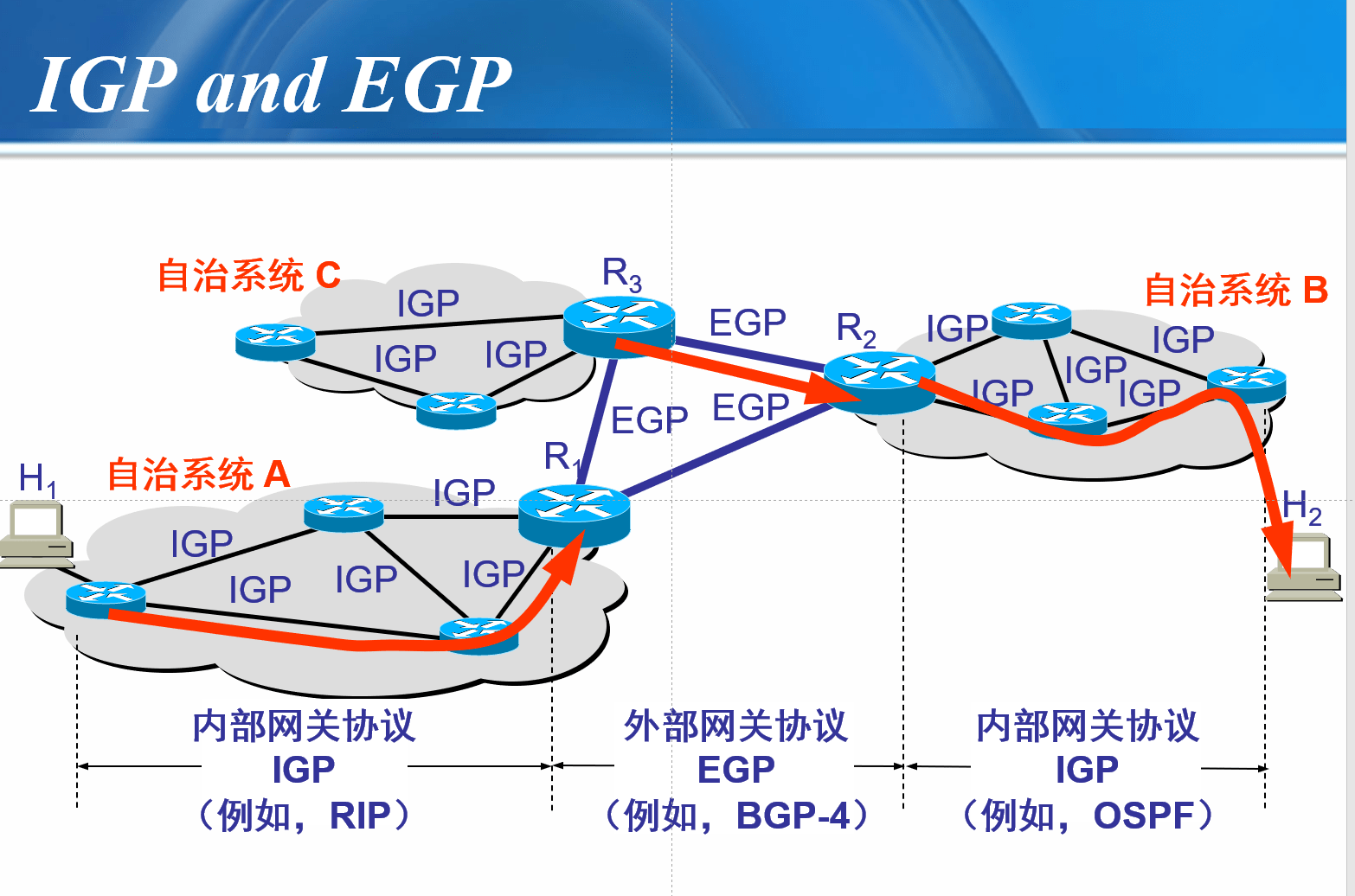
内部网关协议:IGP
RIP协议:选路信息协议
- RIPv1
- RIPv2
-
RIPng



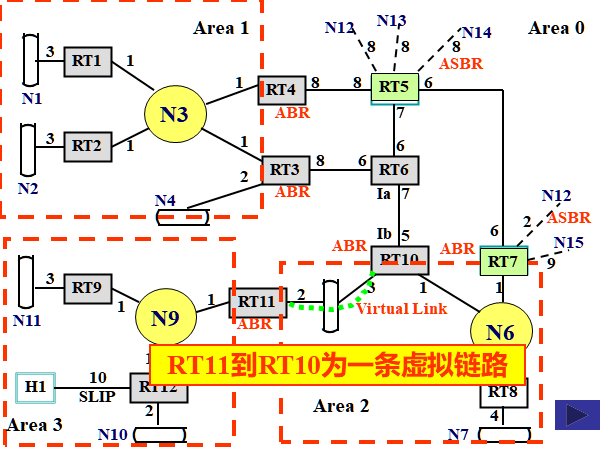
OSPF协议:开放式最短路径优先协议
OSPF的基本操作
OSTF中包含五类数据包
- 问候
- 数据库描述
- 链路状态确认
- 链路状态更新
- 链路状态确认


OSPF报文

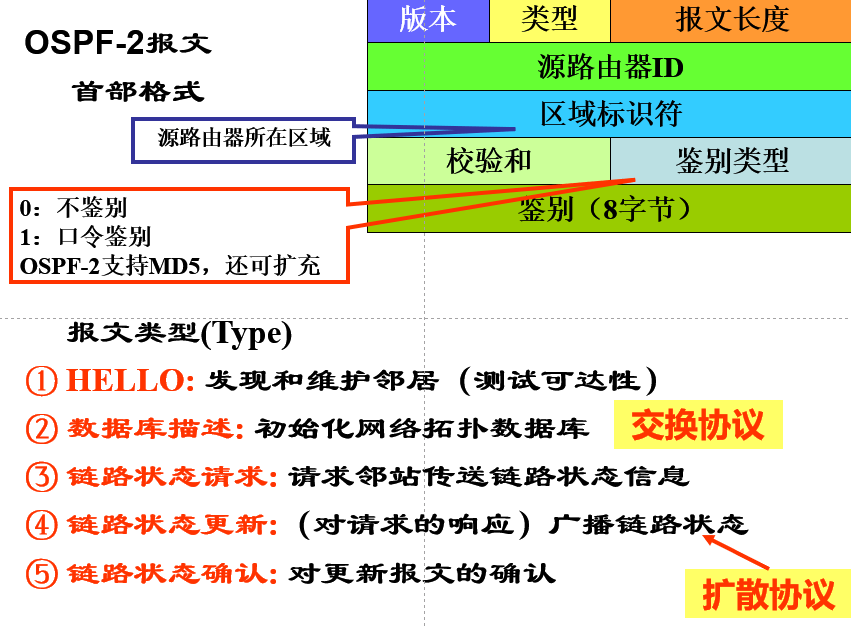
Hello报文
-
作用:
- 1、发现和维护邻居,检测链路是否可用
- 2、选举指定路由器和后备指定路由器
-
3、建立邻接关系


指定路由器(DR)
在一个连接有多个路由器的网络上,指定其中一个路由器负责向外发送该网络中所有链路状态信息
后备指定路由器: DR的接班人(防止DR失效)
优先级: 选举指定路由器和后备指定路由器
数据库描述报文:交换协议
- 作用:相邻的路由器建立连接之后,交换信息来初始化网络拓扑数据库(数据库)

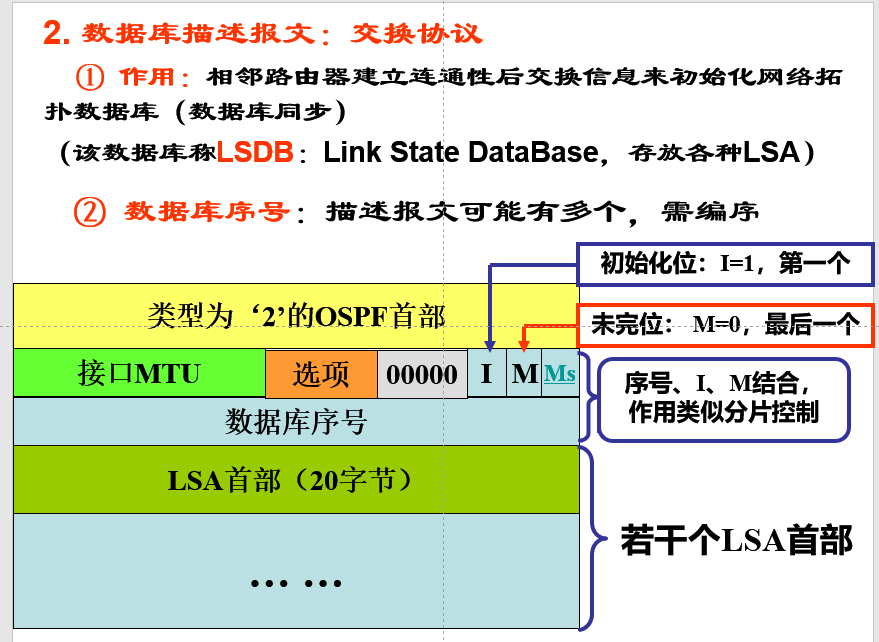



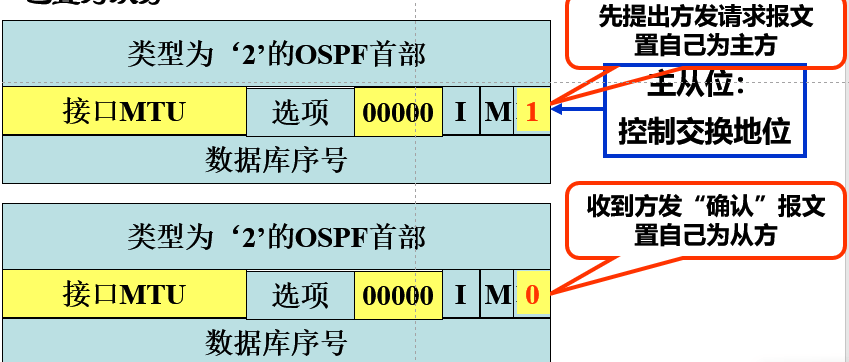
链路状态报文

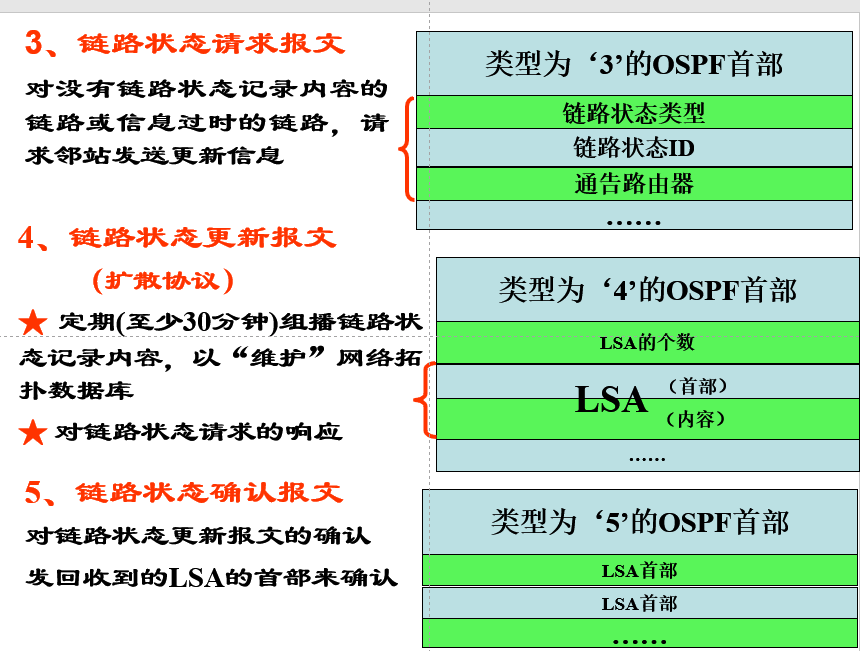
核心内容:链路状态通告LS Acknowledge
也就是链路状态确定报文
首部:20字节





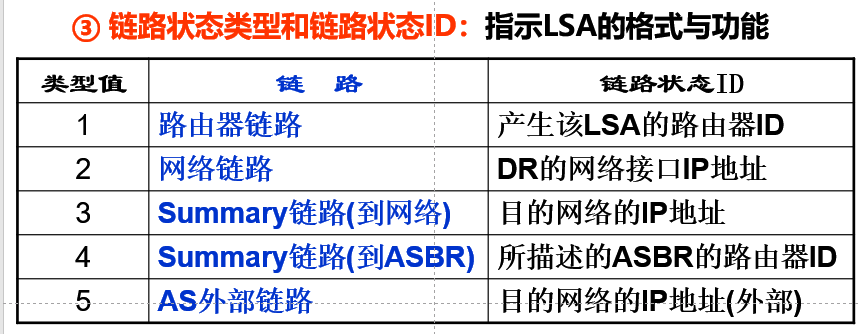
LSA的四种类型

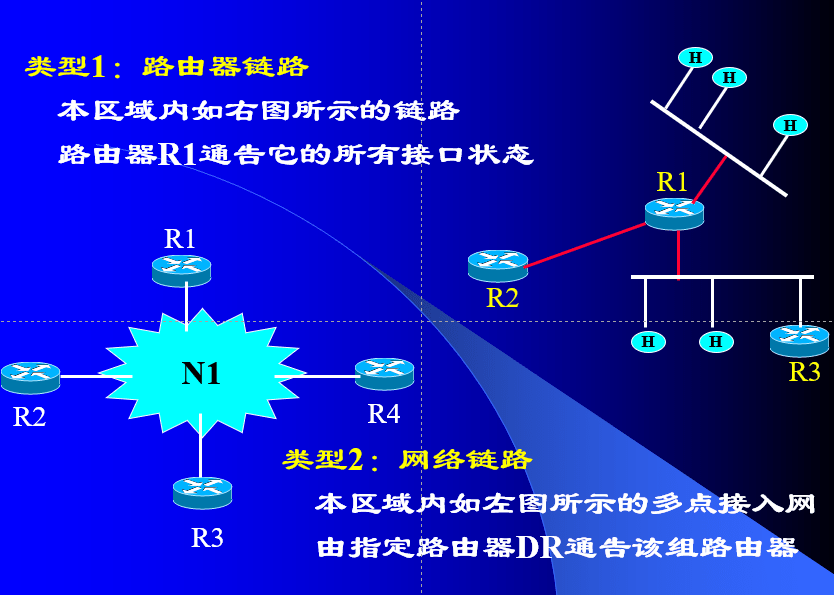

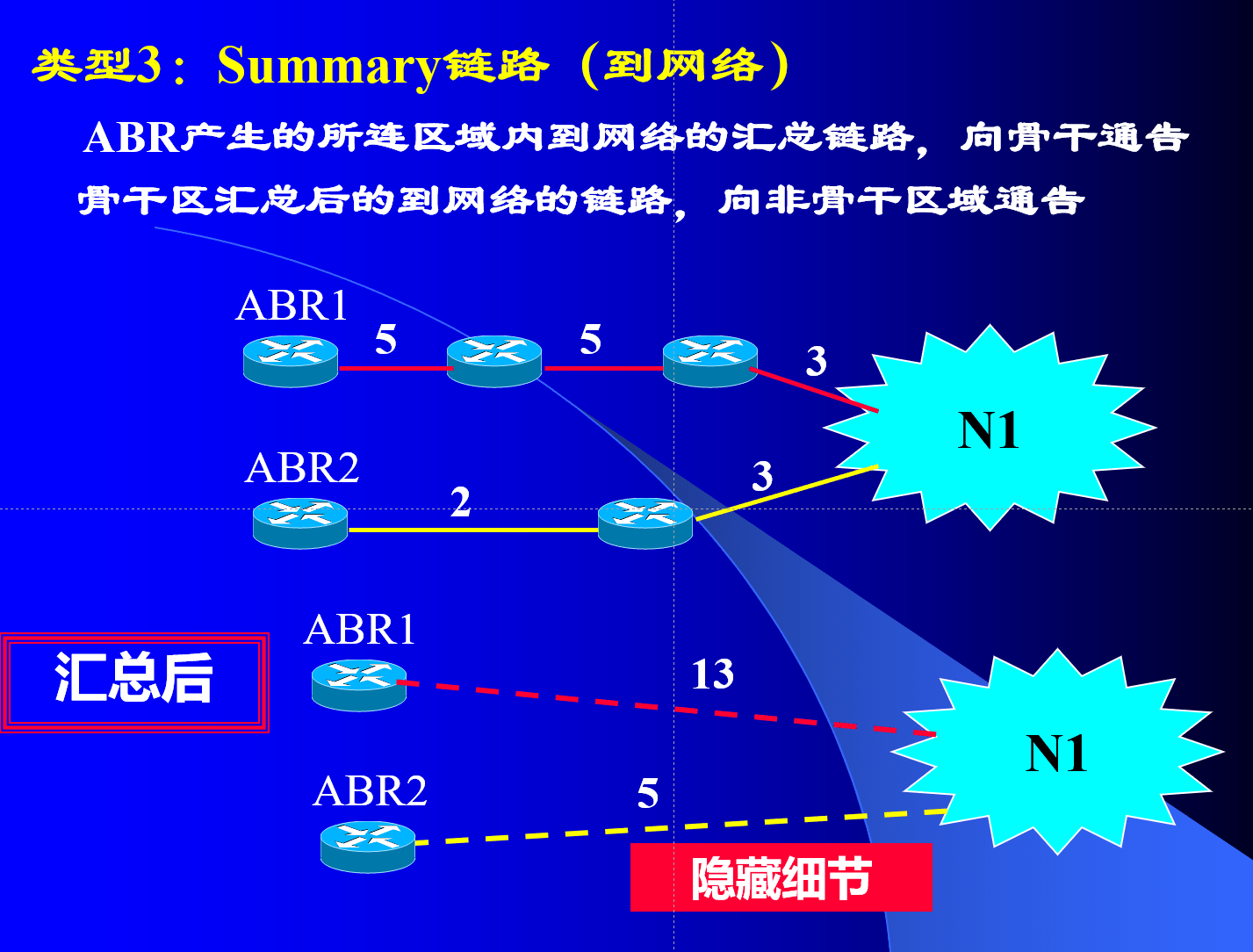



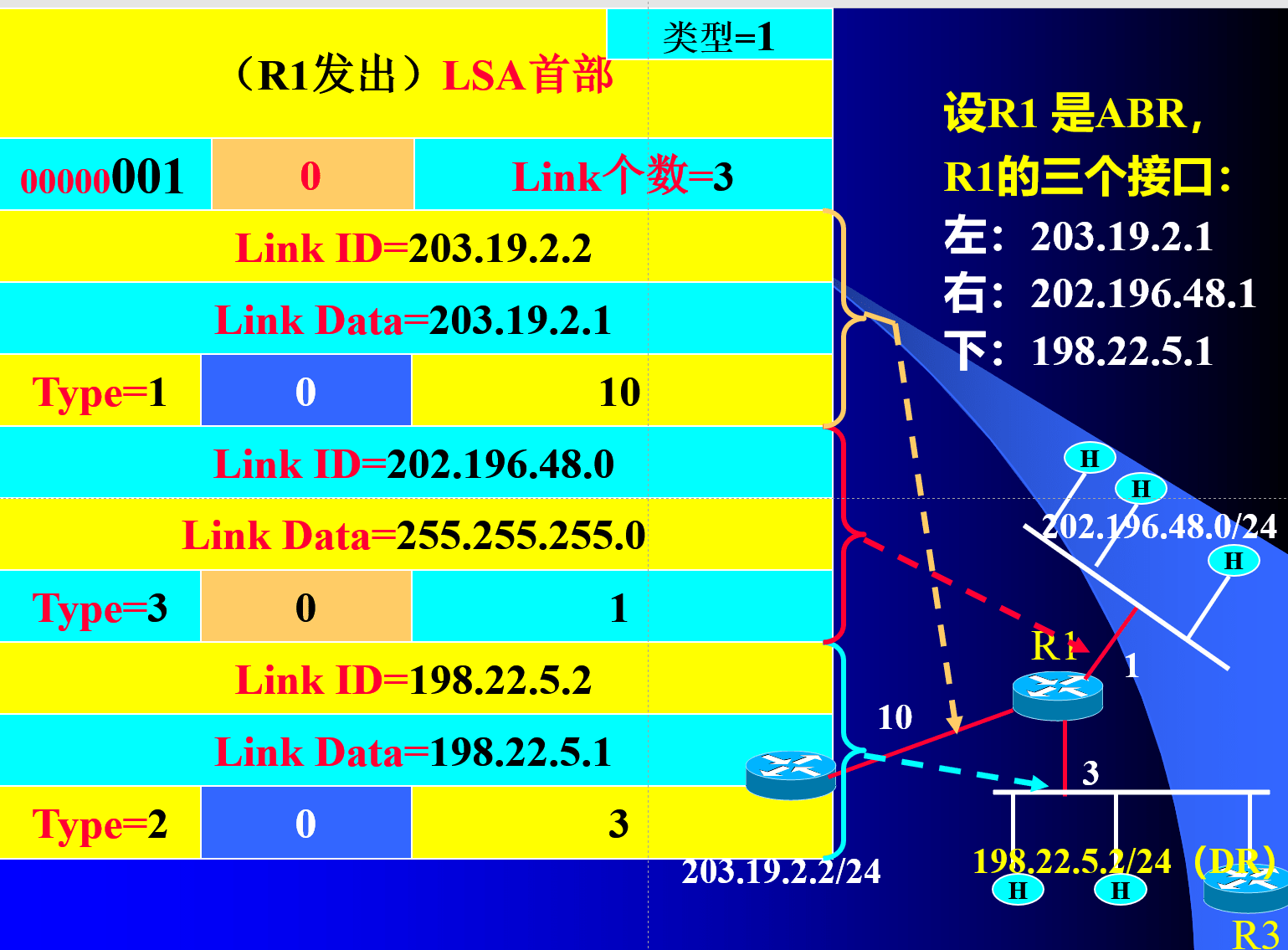

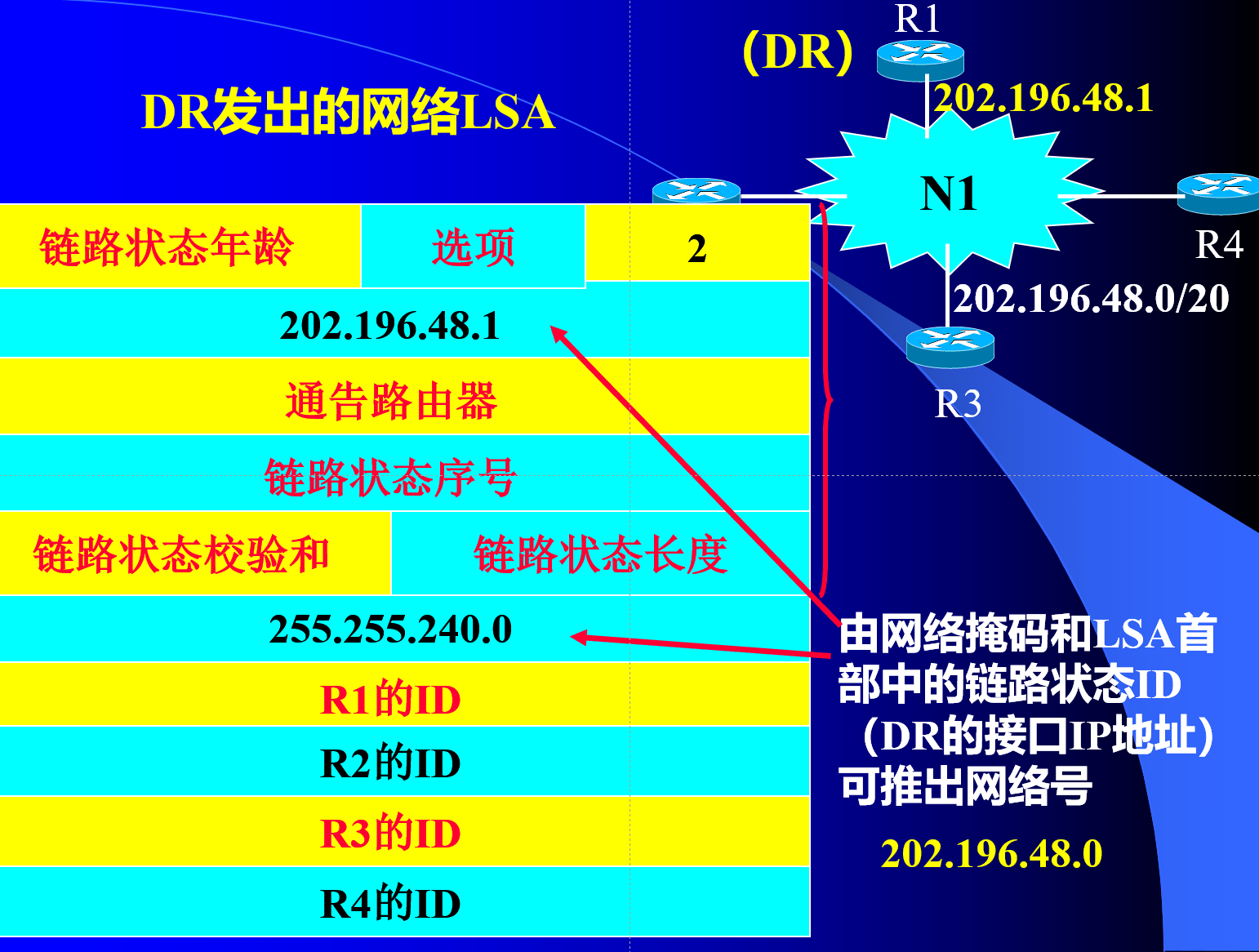
OSPF路由计算


边界网关协议:BGP


Comments | NOTHING